
Loading...
Postulate is the best way to take and share notes for classes, research, and other learning.
Summary of "Playing Atari with Deep Reinforcement Learning"
 Bagavan Sivam
Bagavan SivamSummary of the paper: Playing Atari with Deep Reinforcement Learning
Abstract
The paper demonstrates the first (successful) deep learning model that can learn control policies through high-dimensional sensory inputs using reinforcement learning. This is done with a convolutional neural network that was trained with Q-learning. It takes the input as raw pixels and outputs a value function that estimates for future rewards.
The model was applied to 7 different Atari 2600 games with no changes to the architecture or algorithm, making it the same one for each game. It managed to outperform all previous approaches for 6/7 of the games and had a superhuman level performance on 3/6 of them.
Introduction
One of the biggest challenges in reinforcement learning is controlling the agents directly through high-dimensional sensory inputs (like vision, speech, etc.). Most models that operate in this domain heavily relied on the quality of the feature representations.
However, with advancements in deep learning, we made it possible to extract these features from raw sensory data, which allowed us to create breakthroughs like AI like computer vision and speech recognition.
From a deep learning perspective, there are many challenges with reinforcement learning:
Successful deep learning models use tons of labelled data - RL algorithms learn through a reward-style system.
Deep learning algorithms assume the data is independent - RL data encounters sequences of strongly correlated states.
When the algorithm learns a new behaviour, data distribution in RL changes; deep learning methods assume fixed distributions.
Convolutional neural networks can overcome these challenges and can then be able to learn control policies from raw video data in RL environments. We can train this network with Q-learning and update the weights with stochastic gradient descent (SGD).
To smoothen the training distribution, we will use the replay mechanism to sample previous transitions randomly.
The model was applied to 7 different Atari 2600 games through the Arcade Learning Environment (ALE). Only a single network agent Only can learn to play as many games as possible without providing game-specific info. This means that the paper uses the same architecture and hyper-parameters for all of the games. The model outperforms current models for 6/7 games and surpasses human performance on 3 of them.
Background
Generally, the game scores depend on the whole prior sequence of actions and observations; however, the model only receives feedback about actions only after thousands of time-steps. It is also impossible to fully understand the situation from just the current screen, so we need to consider sequences of actions/observations to learn more game strategies that depend on each sequence.
The goal of this agent is to select certain actions to maximize its future rewards.
If we were to train the algorithm with a basic approach, it just wouldn't be practical as the action-value function would estimate separately for each sequence and won't generalize the model.
This is why the algorithm is model-free and can solve tasks directly using samples from the emulator.
Related Work
TD-Gammon TD-Gammon is a superhuman level backgammon playing program, which was trained through reinforcement learning and self-play. This program used a model-free RL algorithm which is similar to Q-learning. When applying the program to other games like chess and go, the model was less successful.
Deep learning with reinforcement learning Deep neural networks have been used to estimate RL environments. This is done with things like Q-learning. However, there are still some issues with that as the methods are only used in linear functions haven't been extended to nonlinear controls.
Neural Fitted Q-learning (NFQ) This variant of q-learning optimizes the sequences of loss functions using the RProp algorithm. It uses computationally expensive batch updates; however, using SGD updates can make it computationally cheaper. When applying this to real-world tasks, the models proved to be successful. This paper applies a reinforcement learning end-to-end approach directly from visual inputs, which is not the case for NFQs.
Deep Reinforcement Learning
Breakthroughs in deep neural networks have shown to be trained directly through raw inputs and lightweight updates through stochastic gradient descent. If we feed data into deep neural networks, we can learn better representations than regular handcrafted features.
This paper aims to connect reinforcement learning algorithms to deep neural networks so that they can operate directly on RGB images.
This is done through utilizing techniques from the TD-gammon model like its experience replay, which stores the agents' experiences after each time step. Another technique this paper uses is replay memory, which replays the previous iterations to understand the feature data better.
Learning directly from consecutive samples is inefficient as there are strong correlations between samples. This is why we first randomize the samples so that we can reduce the variance of updates.
Preprocessing and Model Architecture Using the direct Atari frames is much more computationally expensive, so we need to preprocess the data. This will be done by reducing the dimensions and converting the RGB to grayscale to make it easier for the model to read the data.
Since the Q maps the history-action pairs to scalar estimates of Q-values, the history and actions are used as inputs for the neural network. The main drawback of this is the type of architecture. Currently, a separate forward pass is required. This is why instead, we will use an architecture that has a separate output unit for every possible action. This is why we are going to be using a convolutional neural network to do so.
The main advantage of this architecture is that it can compute Q-values for all possible actions in the state with only a single forward pass through the network.
Experiment
This model performed on seven different Atari 2600 games - Beam Rider, Breakout, Enduro, Pong, Q*Bert, Seaquest and Space Invaders.
The same network architecture, learning algorithm, and hyperparameter were used to help show how the model is robust/generalized. It also used the RMSProp algorithm for the experiments and trained for over 10 million frames! The paper also used a simple frame-skipping technique so that the agent only sees and selects actions for every other frame instead of every frame to make it less computationally expensive.
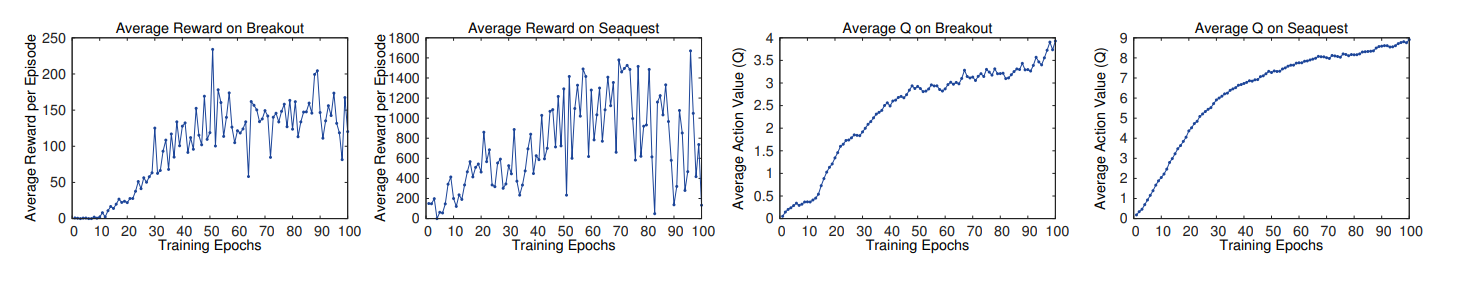
Training and Stability It is easy to track a model's performance during supervised learning tasks but not in reinforcement learning. Since the evaluation metric is the total reward the agent collects in every episode, it is impossible to evaluate the performance while training.
The following graphs show the average reward per episode on the games Breakout and Seaquest.
Visualizing Value Function The following figure shows the value function for the Seaquest game:

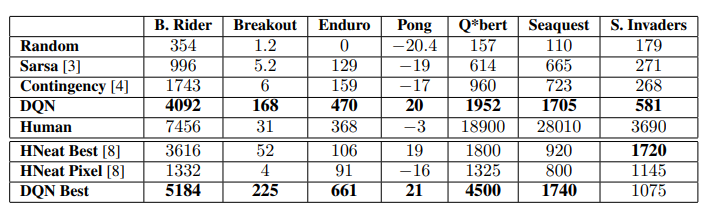
Main Evaluation When comparing the results with other best-performing methods, we notice that our model (DQN) outperforms all other models in 6/7 games.
Conclusion
This paper introduces a new deep learning model for reinforcement learning and can learn difficult contorl policies for Atari 2600 games. We presented a new variant of Q-learning, which combines stochastic minibatch updates and experience replay memory to make the RL training easier for the deep network.
This approach made state-of-the-art results in 6/7 games without any adjustment to the architecture or hyperparameters.
That's pretty much everything that was covered in the paper!
Comments (loading...)
AI Paper Summaries
A bunch of summaries of AI research papers.