
Loading...
Postulate is the best way to take and share notes for classes, research, and other learning.
Summary of "Learning Dexterous In-Hand Manipulation"
 Bagavan Sivam
Bagavan SivamPaper summary of Learning Dexterous In-Hand Manipulation
Abstract
The paper demonstrates the possibility of using reinforcement learning to learn dexterous in-hand manipulation policies, which can perform vision-based object repositioning with a physical robotic hand. They first trained the model in a simulated environment and randomized a ton of material properties, like friction coefficients, the object's appearance, etc. and then transferred the simulated robot to a physical robotic arm.
Without using human data, the model was able to learn and discover human-like movements through training.
Introduction
Dexterous manipulation has been a challenge for decades in the field of autonomous robots. Current robots are designed for specific tasks and are constrained to the setting they are in, limiting learning dexterity. An example of a robotic hand is the Shadow Dexterous Hand, which can perform human-level dexterity.
Previous methods have shown promising results in simulations, but not in the real world as physical robotic pieces. This is because training physical robotic systems are costly and limit the learnt behaviours of the system.
This paper demonstrates a method to train control policies to perform in-hand manipulation, which will then be deployed in a physical robotic hand. The system naturally discovered different grasp types found in humans like the tripod, prismatic, tip pinch grasp, etc. The policies use vision to sense the object's pose rather than physical sensors.
The following image is an outline of the process of how the robot was trained.
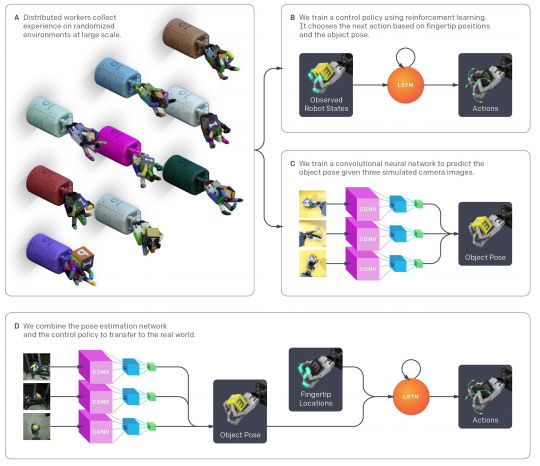
Task and System Overview
The system's goal is to be able to reorient an object placed on the palm of the robotic hand to its desired target. When the goal is achieved, a new goal is created and continues until the robot drops the object. There were two different objects, a block and an octagonal prism.
The system was first simulated and then transferred in a physical robotic arm:

Hardware They used the Shadow Dexterous Hand, which is a humanoid robotic hand with 24 degrees of freedom in each finger. The PhaseSpace motion capture system was used to track the Cartesian position of all of the fingertips.
There were two different setups for the object pose:
PhaseSpace markers to track the object
Balser RGB cameras for vision-based pose estimation
The main intention was to make sure the system could work outside of a lab environment, which is why there weren't any touch sensors in hand.
Simulation They used the MuJoCo physics engines to simulate a physical system and Unity to render the images while training. The model was based on the OpenAI Gym robotics environment; however, it was improved to match physical systems.
Since there was a simulation, there was a "reality gap" between the simulation and the physical robot.
Transferable Simulations
The simulation was an approximation of the real world but was still faced with a dilemma:
You cannot train on a physical robot, as the training would require millions of samples but training only in a simulation won't be able to transfer to a physical system.
To make it transferable, we can modify the basic version of the simulation to a distribution over many simulations.
Observations They used to PhaseSpace markers for observing the fingertips of the robotic arm. They avoided using sensors from the Shadow Dexterous hand as it would be harder to simulate the model.
Randomizations By randomizing most aspects of the simulation, we can generalize the model to a more realistic simulation. The following properties were randomized:
Observation Noise: Added gaussian noise to the policy observations to better mimic noise from reality.
Physics randomization: Parameters (like friction) were randomized at the beginning of each episode.
Unmodeled effects: The robot can also experience effects that are not modelled from the simulation, this is why they used a motor backlash to introduce action delays and noise before applying to the simulation.
Visual appearance randomizations: Camera position, lighting conditions, pose of hand and object, materials, etc. were all randomized when rendering each scene.
Learning Control Policies from State
Policy Architecture The randomizations are continued through each episode, and it is possible for memory augmented policies to identify properties of the environment and adapt its behaviour accordingly. The policy was represented as a recurrent neural network, specifically as an LSTM, with an additional hidden layer and ReLU activations between the input and LSTM.
It was trained with Proximal Policy Optimization (PPO), which requires training of two networks:
Policy network - maps the observations to actions
Value network - predicts the discounted sum of future rewards
They both have the same architecture, but each has independent parameters.
They also use Asymmetric Actor-Critic to exploit the fact that the value network has access to info that you can't get from a physical robot system.
Action and Rewards The action is just the rotation of each joint to a specific angle. This can be either discrete or continuous; however, having it discrete is much easier for training.
The rewards part is the angle away from the destination, minus the previous angle away from the goal. Also, if the destination is -20 and it drops the object, it rewards 5 points.
Distributed Training with Rapid This increases the training speed by a ton and can scale up the PPO without any problems. It will also mean that 1 hour of running the model is the same as approximately two years of experience.
State Estimation from Vision
The policy described previously takes the object's position as input and requires a motion capture system for tracking the object.
Model Architecture:
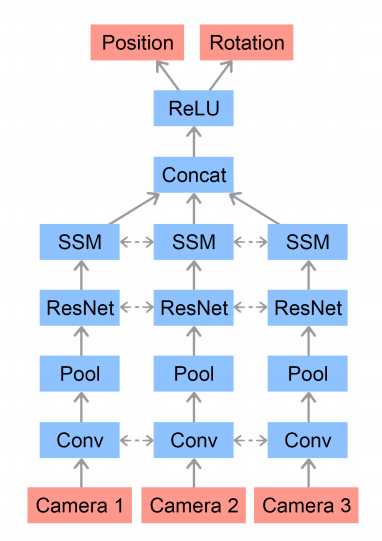
Training We would run the trained policy in the simulator until it has gathered a million states. Training the vision network minimizes the mean squared error between the normalized predictions and the ground-truth ones. As mentioned, we also render the images with randomized appearances.
Results
When deploying the system on the physical robot, they used a block and an octagonal prism as the objects.
Qualitative Results The policies exhibited many human-like grasps, as well as discovered many strategies for in-hand manipulation like finger-pointing, finger gaiting, etc.:

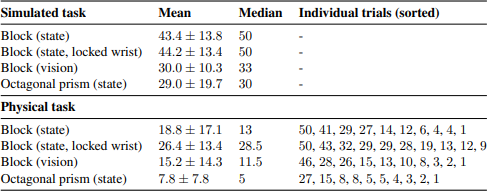
Quantitative Results We can compare the performance of tasks in the simulation to the real robot hand. The simulation can achieve a median of 50 rotations while the physical robot only completed 13 rotations, showing us that the real system did worse than the simulation.
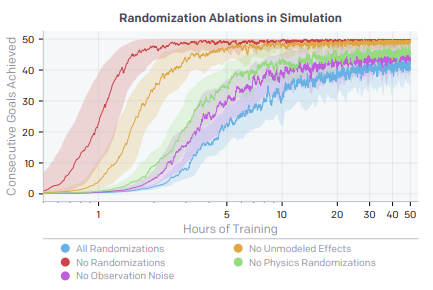
Ablation of Randomization Having more randomness gives the model more training time. However, with randomization, 1.5 hours is the same as 50 hours of regular training.
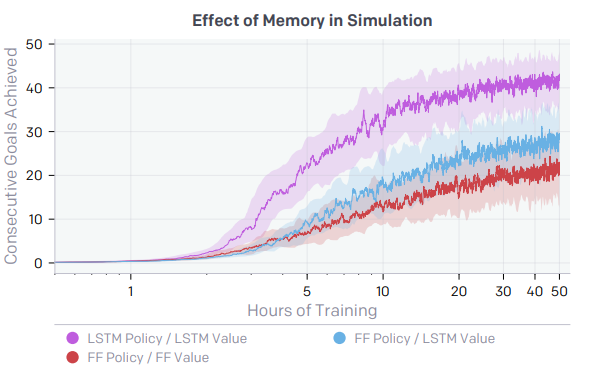
Effects of Memory in Policies Having memory in policies is extremely important as it will help the system better understand and learn new behaviours.
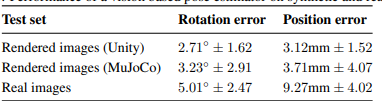
Vision Performance The following table shows the vision-based pose estimator and control policy when transferring it to the real robot:
Related Work
Dexterous Manipulation This has been an active area of research for a long time, and many approached have been developed - however, they require exact models for both the hand and object. This makes it easier to fail.
There are also methods using sensor feedback during its execution, requiring a reasonable model of robot kinematic and dynamics, which is challenging to get.
Deep reinforcement learning has also been successfully used. It allows the system to learn complex manipulations on physical robots. This includes a guided policy search to understand local policies directly on the robot.
Dexterous In-Hand Manipulation Some methods propose generating trajectories for complex dynamic in-hand manipulations, but the results are limited to a simulation. However, things that have been trained with physical robots still have been restricted.
Simulation to Real Transfer There are many approaches, but all of them require tons of access to data. Other techniques like making the policy better through domain randomizations have been used. When used for robotic hands, it was too simple and didn't have enough dexterity.
Conclusion
The paper demonstrated in-hand manipulation skills through reinforcement learning in a simulator and still managed to achieve a high level of dexterity. This is mainly due to the vasts amounts of randomizations on the simulator and large-scale distributed training infrastructure.
A deep reinforcement learning algorithm can be applied for solving many complex real-world robotics problems.
That is pretty much everything that was covered in the paper!
Comments (loading...)
AI Paper Summaries
A bunch of summaries of AI research papers.