
Loading...
Postulate is the best way to take and share notes for classes, research, and other learning.
Summary of "Seq2Seq AI Chatbot with Attention Mechanism
 Bagavan Sivam
Bagavan SivamSummary of the paper: "Seq2Seq AI Chatbot with Attention Mechanism"
Abstract
In the past, we used to build chatbot architectures by relying on hand-written rules/conditional states, which wasn't practical on a broader scale. In 2015, we replaced this architecture with end-end trainable neural networks, which are much more wide-ranged and easier to answer larger queries. There are various types of intelligent models used in the chatbot industry, as the recurrent encoder-decoder models, as well as models adapted from the neural machine translation domain. This paper talks more about developing a Seq2Seq (Sequence to Sequence) AI chatbot with an encoder-decoder of RNNs and LSTM cells.
Introduction
Chatbots are software programs that generate responses based on given input to mimic human conversations - this can either be through text or voice.
These chatbots are being used almost everywhere, from customer services to personal assistants. However, there has been a recent interest in dialogue generation systems which many companies use for question and answering and even conversational agents to aid them.
History and Related Work
Early Approach
Previously, Telegraph released a bot API that provides developers with the ability to create bots by interacting with the Father Bot. These bots were rule-based modelled, which essentially means the developer can write a pattern and a template that the bot can follow to display the template (with a few changes, of course) if it recognizes the pattern. This method made it easy for people to build models; however, it proved hard when faced with complex queries.
Intelligent Models
To solve this problem, we started to utilize machine learning to train bots to learn from existing conversations to solve this problem.
There are two types of intelligent models:
Retrieval-based models
Generative models
Retrieval-based models use responses from the collection of reactions based on the query. These models are not able to generate their own sentences.
Now, the generative models are a bit smarter. They generate their own responses based on the query. This proves to be much more useful; however, it makes it hard for the model to understand proper sentence structure, grammar, etc.
Generative models are the better options when it comes to conversational chatbots.
Recurrent Neural Networks (RNNs)
Recurrent Neural networks are neural networks that can input as variable-length sequence = (x1,..., xn), which then produces a sequence of hidden states h = (h1, ..., hn). This is also known as the unrolling/unfolding of the network.

In each step, the network takes x and hi - 1 and generates a hidden state of h. The hidden state (hi) is then updated by hi = f(Whi−1 + Uxi) . Where W and U are matrices containing the network parameter, and f is a nonlinear activation function.
Vanilla implementation of RNNs is rarely used, as they suffer from the vanishing gradient problem, and it is hard for the RNN to remember previous steps after many steps. This is where LSTMs (long short-term memory) are used to combat the problem of regular RNNs.
Long Short-Term Memory (LSTM)
LSTMs are a special kind of RNN that are capable of long-term dependencies. Like regular RNNs, LSTMs have a form of a chain of repeating modules, but instead of a single neural network (like vanilla RNNs), there are four that especially interact with each other.

Visual Representation of LSTM
The paper didn't go too deep into how LSTMs work, as it is focused more on building a chatbot rather than RNNs.
Encoder-Decoder Model
Encoder-decoder models are generally models that are used in generative models. The basic concept that differentiates rule-based models and neural network-based approaches are in the learning algorithm.
The "Encoder" RNN reads the source of the sentence (input) and transforms it into a fixed-length vector representation. The first hidden state of a "decoder" RNN generates the target sequence (output).
Now, these RNNs can also be replaced with Convolutional Neural Networks (CNNs). CNNs are generally used as an image "encoder." We can use this by pretraining for an image classification task, then using the last hidden layer as input for the RNN decoder.
Using an encoder-decoder model will make it much easier and reduce overload when training and deploying conversational chatbots.
Sequence to Sequence (Seq2Seq)
Sequence to Sequence models consists of two RNNs, an encoder and a decoder.
The encoder takes the input sentence and processes it one word at a time step. The objective of the encoder is to convert a sequence of symbols (a sentence) into a fixed-size vector that will encode the important information of the sequence. Each hidden state of the encoder influences the next hidden state. The final hidden state is essentially the summary of the sequence, which is known as the context/thought vector.
The decoder is really similar to the encoder, and the only difference is that it generates another sequence one word at a time instead.
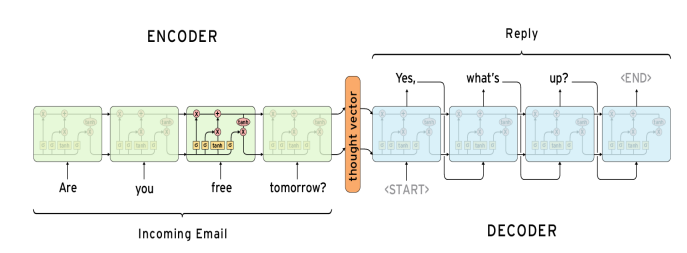
Visual representation of encoder and decoder
There are still challenges with this current model as it won't be able to handle variable-length sequences.
To solve this challenge, we can use one-hot vectors and by using word embedding and padding.
Attention Mechanism
The idea of the attention mechanism is to form a direct short-cut connection between the target and the source. It does this by paying "attention" to relevant sources. This mechanism allows the decoder to selectively look at inputs while decoding, making it easier for the encoder as it doesn't have to use info from every input.

By leveraging the encoder-decoder RNN and the attention mechanism, the Seq2Seq model will be useful when implementing a conversational chatbot.
Dataset
Now that we have a model and architecture to use, we need to find a dataset to train the model on.
We will be using the Cornell movie subtitles corpus dataset, consisting of subtitles and conversations from many scripts and popular films.
Data preprocessing
We need to eliminate some metadata (Move ID, Character ID, etc.) and eliminate separators to only be left with the conversations. After that, we need to divide the conversations into two different lists - questions and responses.
We will then use these tokens for different reasons
<PAD> - used for padding input sentences to make it the same length
<EOS> - used for the end of the sentence
<UNK> - used for unknown words (words not in the vocabulary)
<GO> - used for starting the sentence
Now, there is still a problem with padding, as if there were sentences with 100 words and sentences with 4 words, the padding will get too busy and ultimately lose information in the process.
Bucketing is used to solve this problem as it puts sentences into different "buckets" of different sizes.
[(5, 10), (10, 15), (20, 25), (40, 50)]
This means that if the question and response were four words longs, then it would fall into the (5, 10) bucket.
Word embedding is also used for learning dense representations of words in low dimensional vector spaces (making sure the model can understand short responses/questions)
Training the Model
The model was trained on 3 different configurations with different hyperparameters while using the Adam optimizer. As mentioned, we used the encoder-decoder model, but more specifically, we used BidirectionalLSTMs in the encoder side and an attention mechanism for the decoder side. These two different add-ons will help improve the performance of our model.
Now, given that there is a huge dataset and many components to the architecture of this model, it took a long time to train each configuration, which is why the paper recommends using Google Colab, which allows you to run on their cloud GPU for free!
Results - After training all 3 configurations, the 2nd model performed the best and understood most of the conversation compared to the other ones (as seen below).

Challenges/Limitations
Seq2Seq Chatbot
One of the biggest challenges when building these chatbots is making sure the chatbot is generic. Since we were using machine translation as our domain, generation was treated as a translation problem making it more difficult to solve. Another problem was that the chatbot could not remember previous conversations making it lose that "human-like" feature. Some of the other errors are also related to the data and the quality of the data, as it caused the model to perform below optimum imitation of humans.
Chatbots
Some of the biggest limitations with chatbots is coming from the fact that they are not human. Of course, it makes the chatbots perform more errors and will take many things literally, meaning they won't truly understand some of the given messages. Chatbots are used for providing data and facts and so creating a conversational chatbot is even more difficult.

As you can see from the image above, chatbots cannot recognize human errors.
Conclusion
Many of the techniques used in this paper were able to enhance the encoder-decoder model. They allowed the conversation to be more "human However; some parameters aren't too helpful for making conversational chatbots. Another factor that came into play was making sure the dataset can be further improved for the future. This will allow future chatbots to be more accurate and generic. While training the model, you should always try different combinations of hyperparameters to find the model with the most trying re projects; trying different architectures like using the Luong attention mechanism can also help improve the chatbot.
Comments (loading...)
AI Paper Summaries
A bunch of summaries of AI research papers.