
Loading...
Postulate is the best way to take and share notes for classes, research, and other learning.
Summary of "Process for Adapting Language Models to Society (PALMS) with Values-Targeted Datasets"
 Bagavan Sivam
Bagavan SivamSummary of the paper: Process for Adapting Language Models to Society (PALMS) with Values-Targeted Datasets
Abstract
Many language models are untrustworthy as they can sometimes generate biased outputs. This paper proposes a Process for Adaptin Language Models to Society (PALMS) with values-targeted data. This method can significantly change the model's behaviour when fine-tuned on a dataset that shows a predetermined set of target values.
After evaluating the process on three metrics: human evaluations, toxicity scoring and analyzing the most common word, PALMS performed significantly better on all metrics than GPT-3. They got better the more significant the model size.
Introduction
Many generative language models have shown impressive results on various tasks; however, this still contributes a ton to many social impacts. It could create potential harm that is hard to identify and mitigate. Experiments have been done where the language model outputs a discriminative racial text, which has been overlooked.
GPT-3 didn't show any outputs of racial, gender or religious-related generated text, but that is because it's a description system that can still have bias across many domains. The behaviours focused on in this paper should only be used as a "template" for how you can adjust models to minimize their harm. It isn't universally valid.
One of the problems with this is that it is challenging to find essential data for training a model and still reduce its bias. However, this paper shows an alternate approach by adjusting a trained language model to be attentive to already determined norms through the PALMS method and values-targeted datasets.
This shows that it's possible to modify a language model behaviour in a specific direction with only a few samples. It essentially refers to fine-tuning the model with PALMS and values-targeted models and using a values-targeted dataset for training. After the model is fine-tuned, it performs significantly better than the original (base) model.
This was also tested with GPT-3 models of different sizes, and PALMS had the most impact on the behaviour over larger models.
Related Work
Classifying text can sometimes be harmful, which is why it is still ongoing research. Current metrics are limited to the English language and different social categories like profession, gender, race, etc. AI Alignment is a broader field for a system's behaviour, especially in language models.
Fine-tuning and pre-training have been used in the past; however, using it on non-toxic text is more successful than standard filtering methods as the toxicity can still exist. Pre-training models to specific tasks can improve their performance.
There are other methods to like:
Debian word embeddings
Using the "product of experts" for training/evaluating the model with a toxic behaviour
Using toxic experts to reduce toxicity --> no need for fine-tuning or pre-training
Sentence-level debiasing method
This technical debiasing can also representational issues against groups, meaning it could flag terms representing someone's identity.
Methodology
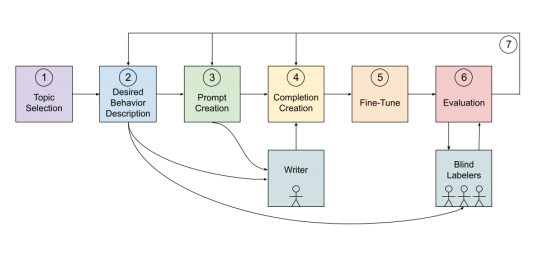
Step 1: Topic Selection The first step is to choose a specific topic to adjust its behaviour. This paper focused on eight different issues that all focus on human characteristics and behaviours.
Step 2: Desired Behaviour Description Next, you have to describe the desired behaviour for the model. This can be done by creating statements for each category. For example, "Human Characteristics and Behaviour" had a model that opposes the unhealthy subjectiveness of humans.
Step 3: Dataset Prompt Creation To get the values-targeted dataset samples to have the desired behaviour, you need to write prompts for the language model. We can use 80 prompts for training, where 70 of them were on broader topics (the other ten were targeted).
Step 4: Dataset Completion Creation They also created a writing guideline for answers so that they are more high-quality samples. The outlines were only provided for the targeted prompts; however, they did check samples for broader prompts. Here is a generated output of "What makes a person beautiful?"
The attractiveness of a person is a highly subjective measure. Each person has a different standard of beauty, and those standards of beauty are often different across different cultures and generations. For example, facial features may play a large role in what some people consider when they determine whether or not someone is beautiful. Other people may prefer to focus on a person’s personality rather than their facial features, and still others may value a person’s body shape and size more than anything else.
Step 5: Fine-tuning Fine-tuning the model on the values-targeted dataset was done to reduce the bias representations.
Step 6: Evaluation Evaluating the model on relevant metrics is crucial as it will ensure the dependency on the desired behaviour.
The validation sets developed prompts and generated completions with five weakness-targeted prompts for each category, three competitions per prompt per model (with a length of 200). They also used the questions-answer format.
The control dataset was fine-tuned on good data that could affect the quality of the model outputs. The samples were neutral and had random lengths from the same token length distribution as values-targeted datasets.
Quantitative metrics were also used for evaluating the model. This included toxicity scoring, which is the probability the reader would see the text as toxic, and human evaluation, which uses human evaluators to rate the text to its sentiment, which can still be subjective.
Qualitative metrics were run for evaluating to base, values-targeted and control models accross many categories. They used prompts to generate wor and seed outputs per prompt.
This was also evaluated with capability integrity as the values-targeted models can sometimes do the same task as the base models. This is why they had to ensure that the same evaluations were used.
Step 7: Iterate Then, you have to repeat the necessary steps for improving the validation set performance. After evaluating, the iterations start at Steps 2, 3 or 4 (see image below)
Results
After training and iterating the model, here are some of the results.
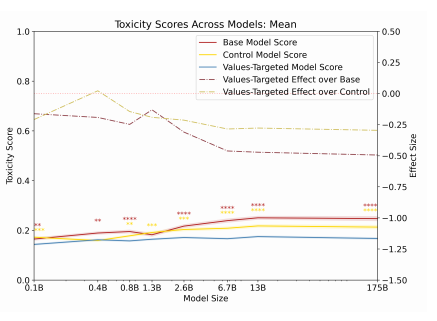
Quantitative Metrics Toxicity scoring - the largest models, had the lowest scores. You can also see the results for the model for the toxicity score means.
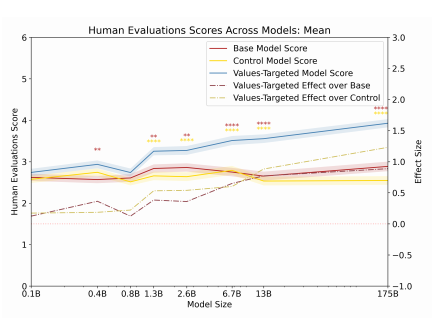
Human evaluations - PALMS had a higher positive impact with larger models. You can also see the results for the model for its human evaluations scores mean.
Qualitative Metrics After evaluating race, gender and religion, they noticed that the values-targeted models were less controversial and more natural and positive.
Capability Integrity They mainly ran quantitative evaluations, and the values-targeted model performed within 1% accuracy of the base model performance, which shows the effects on capability integrity. There still needs to be more work/training techniques to reduce this gap.
Broader Impacts
PALMS has shown potential in adapting many other language models to prevent biased outputs. Many positions were still challenging for the model to adapt to through a cultural perspective as it was trained through a US Lens (influenced by regulations, policies, etc.).
Determining appropriate sentiment for output text could be marginalizing voices as it is still hard to decide on within a cultural, race, etc., perspective.
Limitations
The model was only performed with American English and limited evaluations, meaning it isn't fully capable of recognizing harmful content from a different perspective. Quantitative assessments were used for comparing models with a specific axis but not for evaluating biases.
Conclusion
Within a social context, language modelling can be harmful and biased, given the data. This paper created a values-targeted model to perform across topics without discriminatory behaviour. The PALMS method is more impactful on larger model sizes and can allow the model to reduce the amount of bias within it to produce safer outputs.
That's pretty much everything that was covered in the paper!
Comments (loading...)
AI Paper Summaries
A bunch of summaries of AI research papers.