
Loading...
Postulate is the best way to take and share notes for classes, research, and other learning.
Paper Summary: "Feature Pyramid Networks for Object Detection"
 Dickson Wu
Dickson WuCNN'sPaper Summary: "Feature Pyramid Networks for Object Detection"
TL;DR - FPN's exploit the intrinsic property of CNN's to build a feature pyramid. We extract features from layers of the CNN, and then connect them together such that we end up with a feature pyramid!
Importance - CNN's have the power to unlock massive performance boosts through feature pyramids, but CNN's don't use them due to it being computationally expensive to train and use. This paper introduces FPN's which unlock the power of feature pyramids, without sacrificing performance.
Abstract:
Feature pyramids = good for recognition systems. But CNN's aren't using them because it's too computationally expensive.
This paper goes about solving the problem by exploiting an inherent property of CNN's to create feature pyramids without that much extra cost. It's a topdown architecture with lateral connections - called a feature pyramid network.
When they applied FPN to a basic Faster R-CNN system - they beat all other single model entries and achieved state-of-the-art results. Also runs at 6 fps, so it's practical.
Introduction:
In object recognition, we have to detect objects at all sorts of different scales. Pyramids can tackle this easily because the object will be detected at one of the levels of the network.
We used to use featured image pyramids a lot when hand engineering features - and were critical to achieving good results. For the most part, we've replaced hand engineering features and opted for CNNs since they're robust to scaling.
But we still need pyramids. All top entries use pyramids - thus we can't ditch them. They're strong because all levels of the image are represented well.
But it's incredibly hard to incorporate them into CNNs. Inference time takes 4 times longer + we can't even train them on the pyramids since they're too memory intensive.
Currently, CNNs are using feature hierarchy to compute multi-scale feature representations - which have an inherent pyramidal shape. It's not as good as the pyramids because there are semantic gaps due to different gaps.
Single Shot Detectors attempt to use the feature hierarchy like it was a pyramid. But SSDs aren't using already computed layers and build the pyramid from high up in the network and adding new layers - they miss an opportunity to reuse layers - which is important for feature hierarchy.
This paper aims to use the natural pyramid shape of CNN's Feature hierarchy that's strong at all scales. They combine 4 things together: low-resolution, strong features (high resolution), weak features (top-down pathways), and lateral connections.
Other work also uses top-down + skip connections. But they're building the feature map and then using it for predictions. We're making this pyramid where predictions are made at each level.
They applied FPN to a basic Faster R-CNN and beat all other single model entries + obtained state-of-the-art for other metrics too. And we can build on top of this to obtain masks and segmentation. Also, the pyramid can be trained on, and the test time doesn't increase that much.

Comparing the pyramids: Featurized Image pyramid is slow. But Single feature map + Pyramidal feature hierarchy are pretty fast. But FPN is more accurate and still as fast -> Because when they create that secondary pyramid on the right it’s able to enrich every layer such that we have an easier time to do stuff with it. a, b, and c don’t let them enrich each other, thus the layers are more disjointed (they have large semantic gaps).
Related Work:
Hand engineered Features + early neural networks:
HOG + SIFT pyramids are computed over the entire image pyramid. They were used for lots of things like image classification, object detection, human pose estimation + more stuff.
We made them faster by making them sparse and then interpolating missing levels. Also, early work with CNN's used image pyramids too!
Deep CNN Object detectors:
CNNs = major improvements in terms of accuracy. Overfeat used CNNs for sliding windows on image pyramids. R-CNN used region proposals with CNN's. SPPnet demonstrated that they can do the region-based detectors more efficiently. And we have modern ones like Fast R-CNN and Faster R-CNN which odes everything at once scale - but multi-scale detections are still better with smaller objects {Interesting because YOLO also wasn't able to detect smaller objects too}.
Methods using Multiple Layers:
We can use multiple layers in CNNs to detect stuff. FCN sums the partial scores of each category of multiple scales. Other methods concatenate feature layers before predictions. SSD does it without combining the layers.
Recent methods use lateral/skip connections. Like U-Net, they associate low-level feature maps across resolutions. Other networks adopt pyramidical shapes but act differently than featured image pyramids.
Feature Pyramid Networks:
CNN's naturally have pyramidal features (going from low to high levels) which we use to build the pyramid --> Which yields FPNs! They're general-purpose so we can apply them to whatever we want.
Input = any sized input, we output proportionally sized feature maps of different levels. We don't care what type of backbone CNN we use, FPN's work regardless. There are 3 steps in which we construct our pyramid:
Bottom-up pathway:
This is the backbone CNN. The CNN undergoes lots of convolutions, pooling etc etc. In general, the image decreases in size (hence the pyramid shape). But it isn't a constant decrease, we sometimes have the same shape output multiple layers in a row.
We call layers that have the same output size as a stage. And we draw from the last layer of each stage (since it has the strongest features). When we draw from it, we're using it to create our pyramid.
Top-Down pathway + Lateral connections:
The higher you go, the richer the features are (but also the coarser the images). We want to extract this richness, so we funnel the higher layers down to the lower layers. In addition, we enrich the connection by connecting it with the lateral connection (from the bottom up pathway).

Since the image is coarser, we upsample the image to match the dimension of the lower layers. To start the chain we just do a 1x1 of the bottom-up pathway, and then we funnel it downwards. We're going to get some aliasing effect from the upsampling (aka horrible effect that screws with the image) so we pass a 3x3 convolution to reduce it. Now we're done and we have the final feature maps!
We also have to fix the number of channels we have (since all layers are sharing the same classifiers + regressors. This design = super simple, and that's what the authors are aiming for. We can improve it by having more sophisticated blocks, or better connections modules.
Applications:
First, we're going to go over FPN's for RPN (region proposal network). Then we go over it for Fast R-CNN.
RPNs:
RPN = we have a sub-network that's evaluating the 3x3 sliding window. It's performing object classification + bounding box regression. The network = 3x3 conv layer + two 1x1 convolutions as the head (because it's doing the classification + regression). The object criterion + bounding box regression = defined with respect to anchors (pre-defined scales + aspect ratios).
We're going to adapt RPN to FPN's. We attach the head (3x3 + two 1x1's) to each layer of the feature pyramid. No need for multi-scale anchors (since we're scanning all layers) single scale = is good. There are 5 anchors with 3 different aspect ratios, meaning we have 15 anchors over the whole pyramid.
For training, we're just doing the IoU of the anchors and the ground truth. (same training as usual). We assign ground truths to anchors, which are then associated with the levels. We can share parameters across heads too (with no performance difference if we didn't share them).
Fast R-CNN:
Fast R-CNN takes in Region of Interest Pooling, but it often does it at a single scale. So we just implement FPN by assigning ROI to different scales of the pyramid.
We make our FPN feed into the region-based detectors as if they were image pyramids. We can assign regions to a level of the pyramid using this formula:

Explanation:
k = the level of the pyramid we're assigning the region to
k_0 = the target level which we think it should be mapped to
w,h = width, height
Intuitively, if we have a scale that's smaller (whatever inside of the parathesis = 1/2) then we have to assign it to a finer resolution (smaller). The pre-set k_0 value is 4 (adopted from another paper)
We attach predictor heads to all the RoIs - they share the same parameters regardless of level. [they talk about the specific architechture layers].
Experiments on Object Detection:
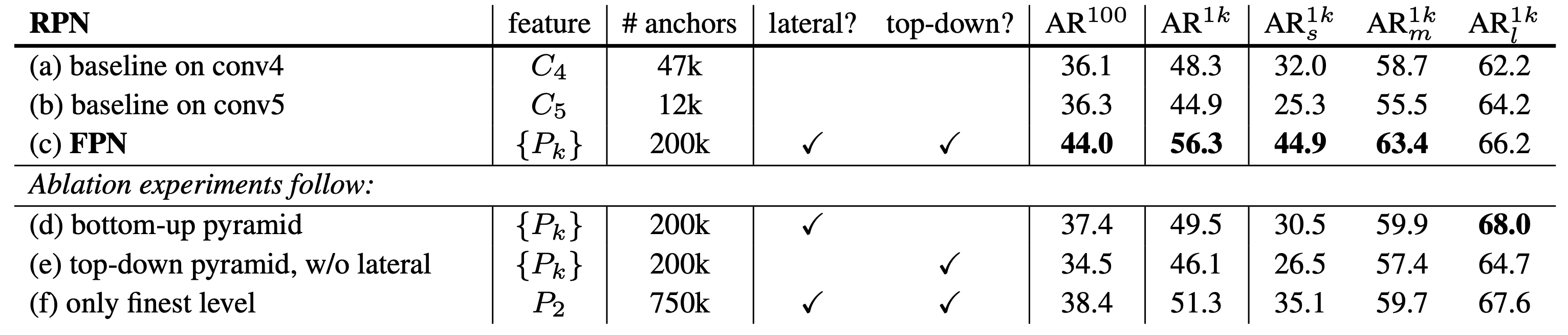
They tested RPN (with a ton of ablations & Fast R-CNN). Here's all the results:




Extensions: Segmentaiton Proposals:
Just like how we could add extra heads on Faster-RCNN (like mask, and mesh) we can add some heads to FPNs. They did it with masks and the architecture ends up looking like this:

And they achieved state of the art:

Conclusion:
FPNs are a clean and simple way of integrating feature pyramids in CNN's without sacrificing computation. Using FPNs, they achieved state-of-the-art results when applied to a basic Fast R-CNN. Finally, even though CNN's are incredibly powerful and robust, we still need to explicitly direct them to the multi-scale ranges.
Thanks to Saurabh Kumar for recommending this paper + reinforcing my understanding!
Comments (loading...)
ML Paper Collection
A Collection of Summaries of my favourite ML papers!