
Loading...
Postulate is the best way to take and share notes for classes, research, and other learning.
Paper Summary: "SpinalNet: Deep Neural Network with Gradual Input"
 Dickson Wu
Dickson WuPaper Summary: "SpinalNet: Deep Neural Network with Gradual Input"
TL;DR + Importance - We replicate the spinal cord system of humans into the Fully connected layers of NN's to get SpinalNet - this reduces computation and increases the performance. This is done by splitting up the inputs, introducing them gradually and repetitively.
Abstract:
NN's are awesome - but if the input size is big then we have a lot of parameters - let's fix that by emulating the human spine, with SpineNet. Higher accuracy, less computational resources.
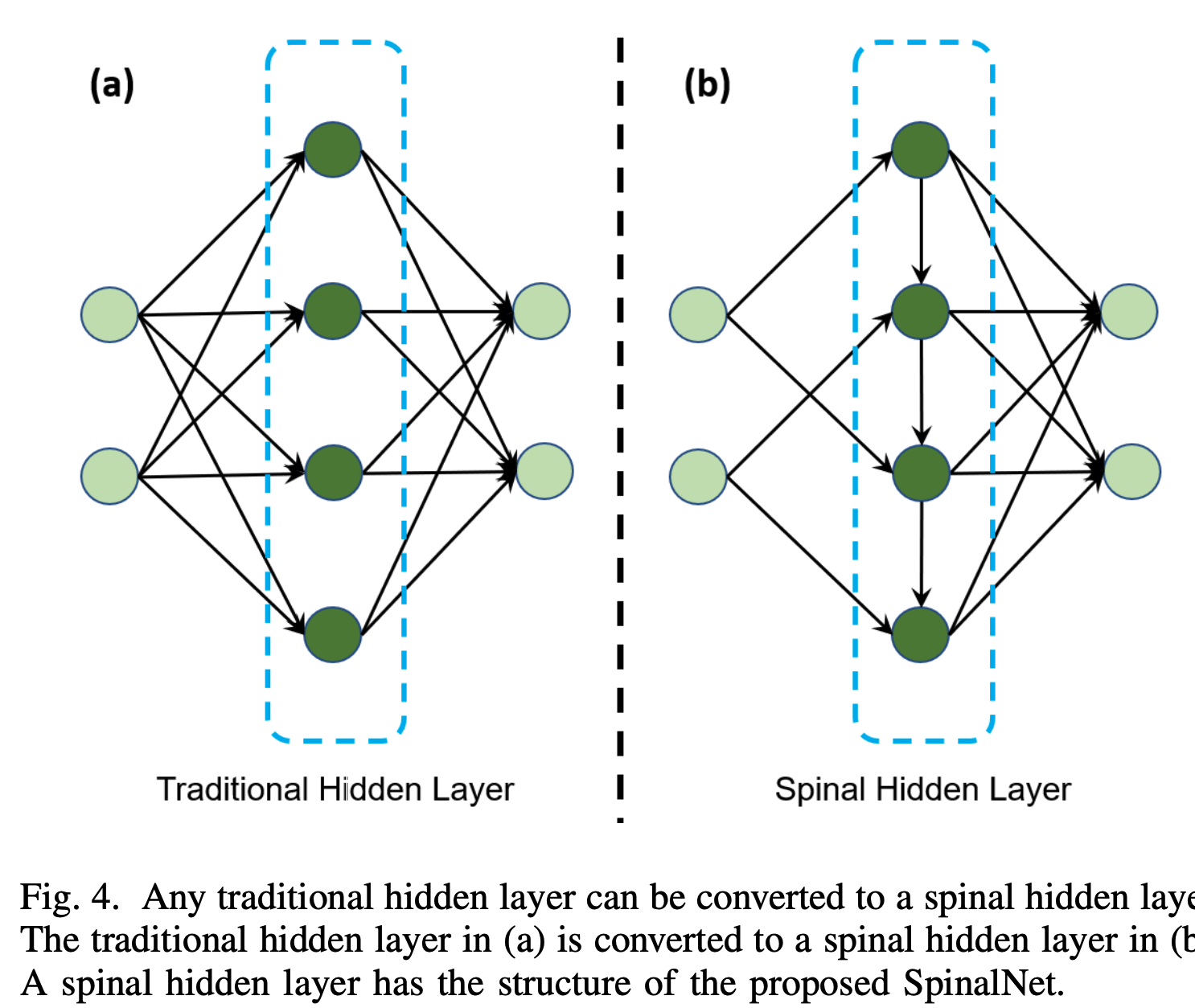
Traditional NN's: inputs to first layer --> second layer --> third layer etc. SpinalNet on the other hand has a totally different architecture. Each hidden layer has 3 sectors: Input row, intermediate row, and output row. And there are very few neurons in here.
The inputs and the outputs of previous layers aren't all fed into every single neuron. Instead, each hidden layer will receive segments of previous layers - which reduces parameters. Each hidden layer will contribute to the output row (so no vanishing gradient problem)
They achieve SOTA on many different datasets with lower computation costs.
Introduction:
We usually want our input to be as big as possible - since it usually improves accuracy. But first hidden layer = critical. If we make it too small, we won't pass on all the important information. If it's too big then we have too many parameters. Also, there's the vanishing gradient problem for NN's, gradient is high near outputs, but almost 0 at inputs.
The human brain also receives a ton of signals from our skin, pressure, heat, vibration, texture, hardness etc... And we have to thank our spinal cord neurons for that. The spinal cord receives touch information from multiple locations - each associated with different connection points with the spinal cord:
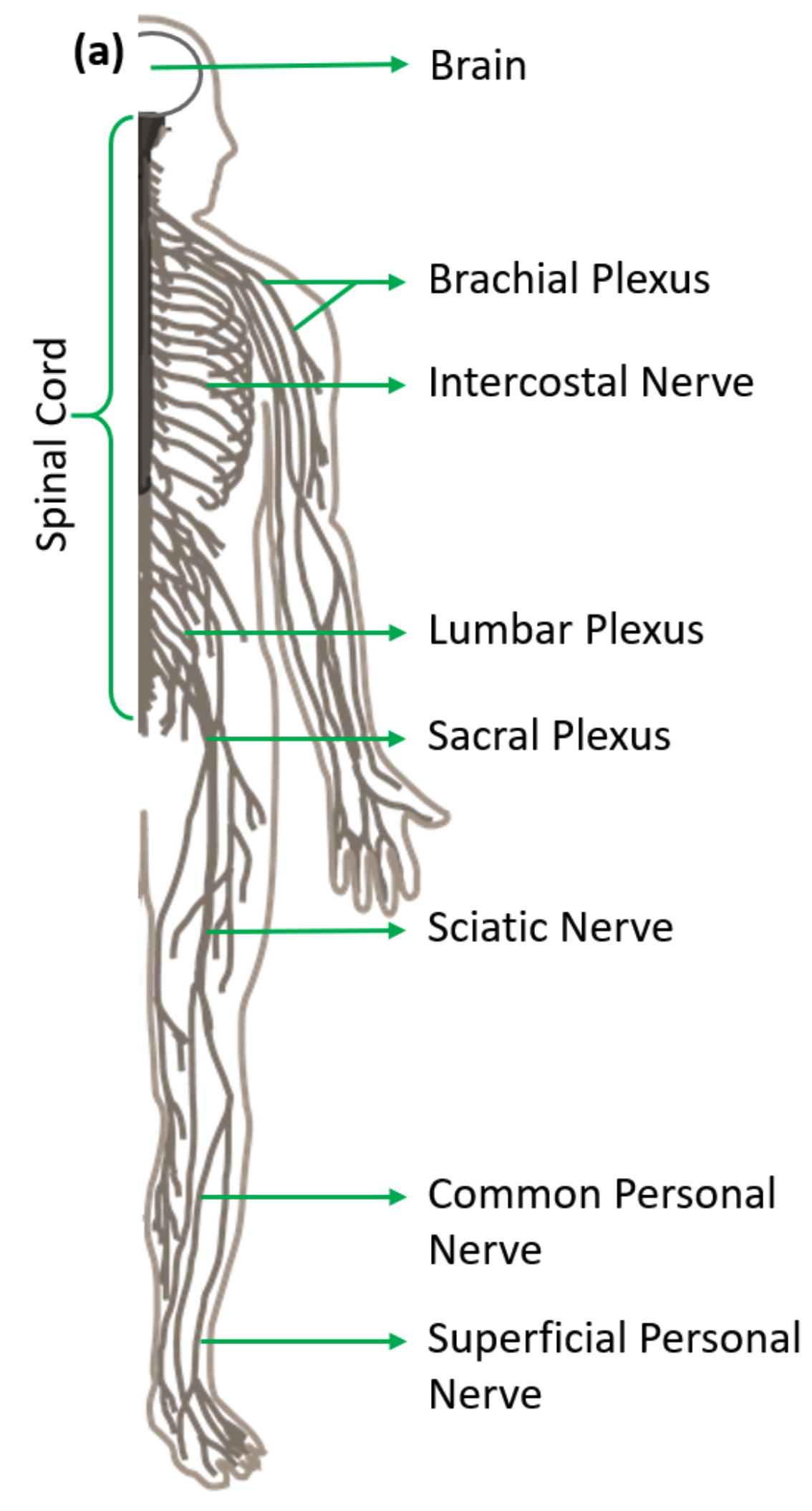
CNN's were inspired by the cat's visual cortex. This paper was inspired by human spinal architecture.
One way we can reduce computation is through pooling - but we lose information in the process
One way to avoid the vanishing gradient problem is through ResNet and DenseNet.
ResNet has skip connections across layers, thus we can have super deep architectures, and the gradient is still a-okay near the inputs. But there's a marginal improvement per increased depth, plus we have diminishing feature reuse - some people have made their NN's shallower and wider.
DenseNet every single layer be connected to every other layer. Feature reuse and gradients are kept. But it's really computationally expensive. Adaptive Structural Learning instead chooses which neurons to connect during training - but that's also computationally intensive, so stuck with shallow NN's.
This paper aims to reduce the computation intensity and increase performance. SpinalNet has gradual and repetitive inputs --> Thus fewer parameters.
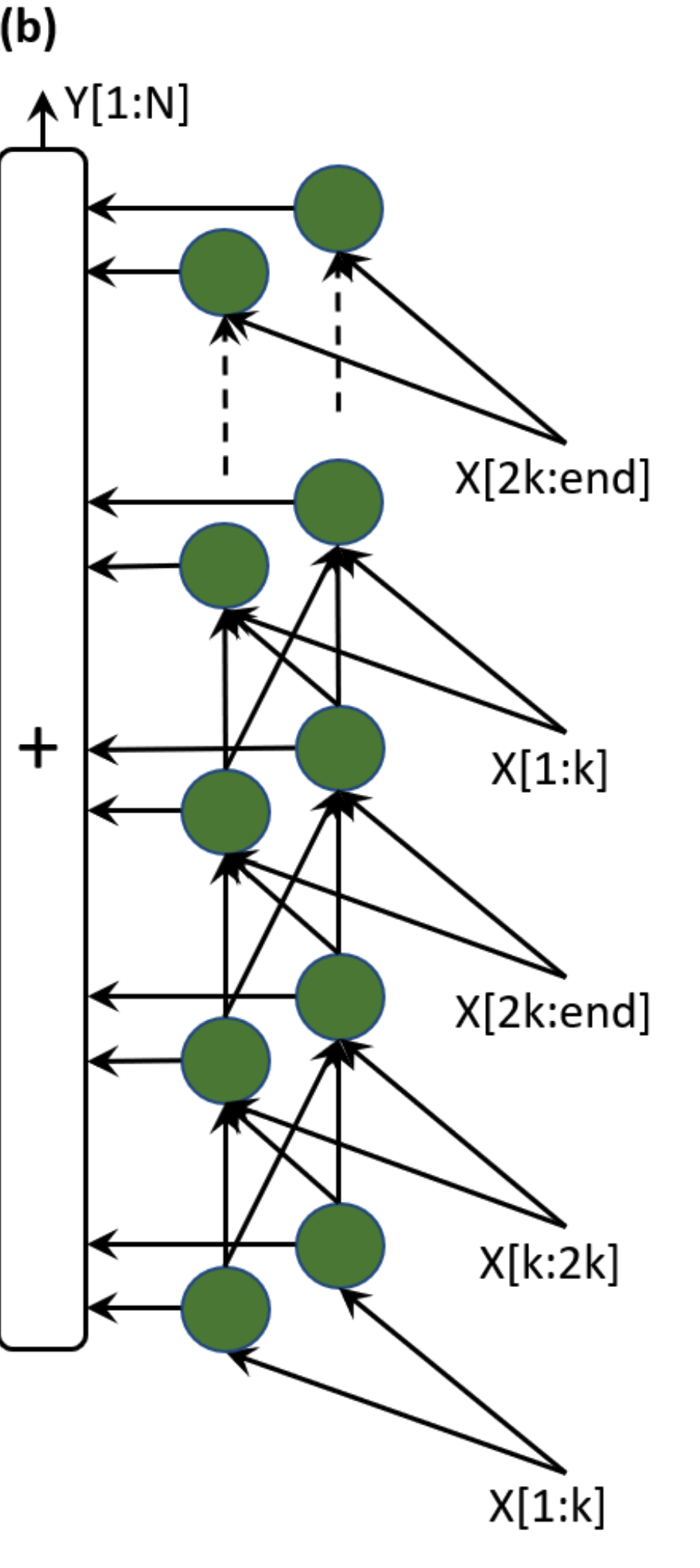
Theoretical Background:
Two types of NN's = Convolutional and Non-convolutional. Non-convolutional = Fully connected inputs, hidden + outputs. Deep CNN's have convolutional layers + Fully connected, but parameters also increase due to convolutions + flattening.
We use pooling to decrease the input size, learn more mappings, and combine the outputs on a larger scale, but we lose out on information. Pooling is flattened and can be used in fully connected layers.
Human Somatosensory System + Spinal Cord:
Sensory neurons go through a complex network (nerve plexus) to reach multiple vertebrae gradually. Below is what a part of the nerve plexus looks like:
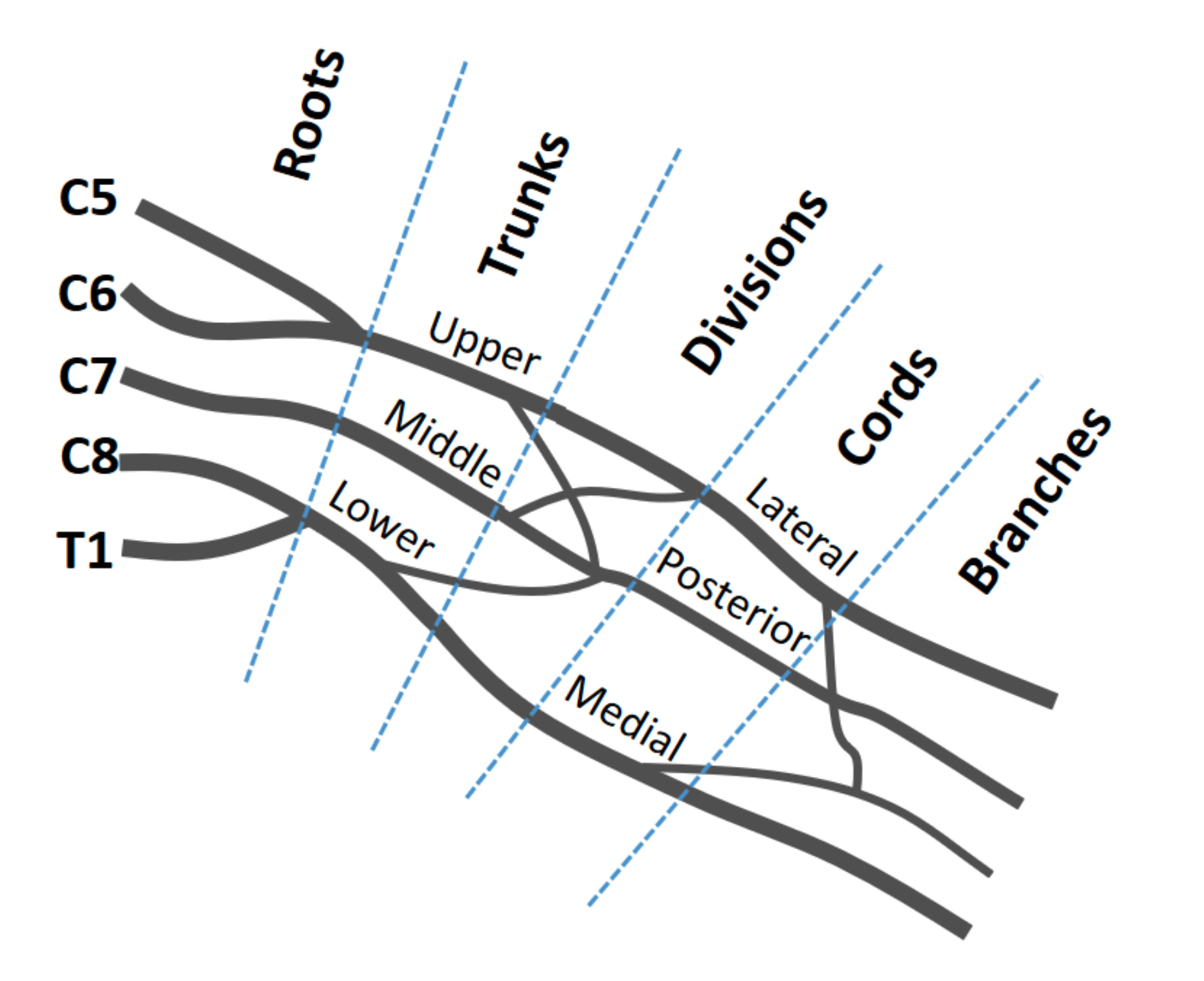
Also, our tactile system is much more stable than other systems (vision or audio) --> Since there are a lot fewer touch-blind people than vision or audio blind people.
The neurons the exit the vertebral column tells the brain what's going on, and information can be sent back to take action. The spinal cord can even take action even without the signal getting to the brain yet (reflex).
Proposed SpinalNet:
SpinalNet also takes in inputs gradually and repetitively, has local outputs (like the reflexes) and contributes to the global output (to the brain).
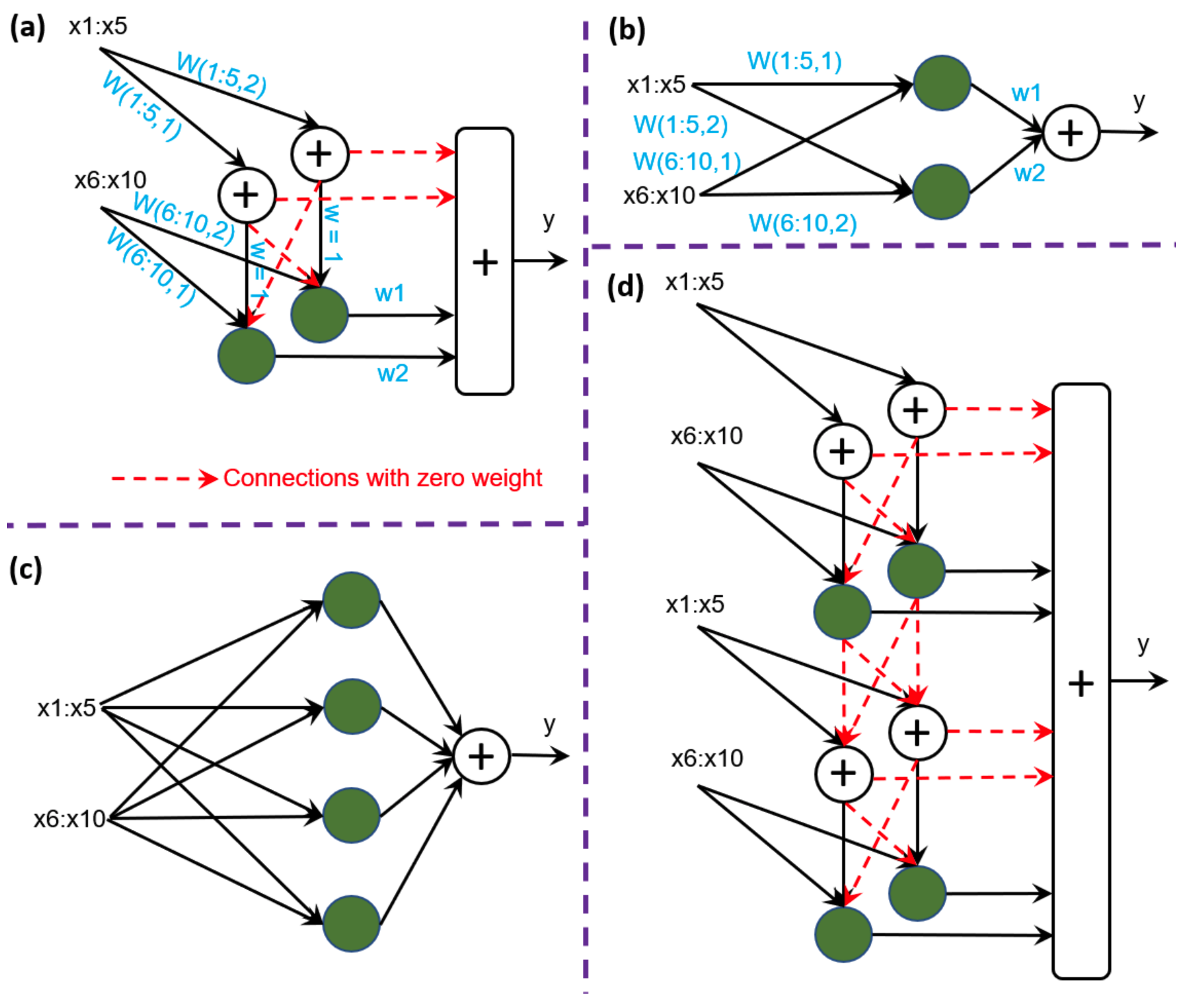
Alright let's look at our NN right now:
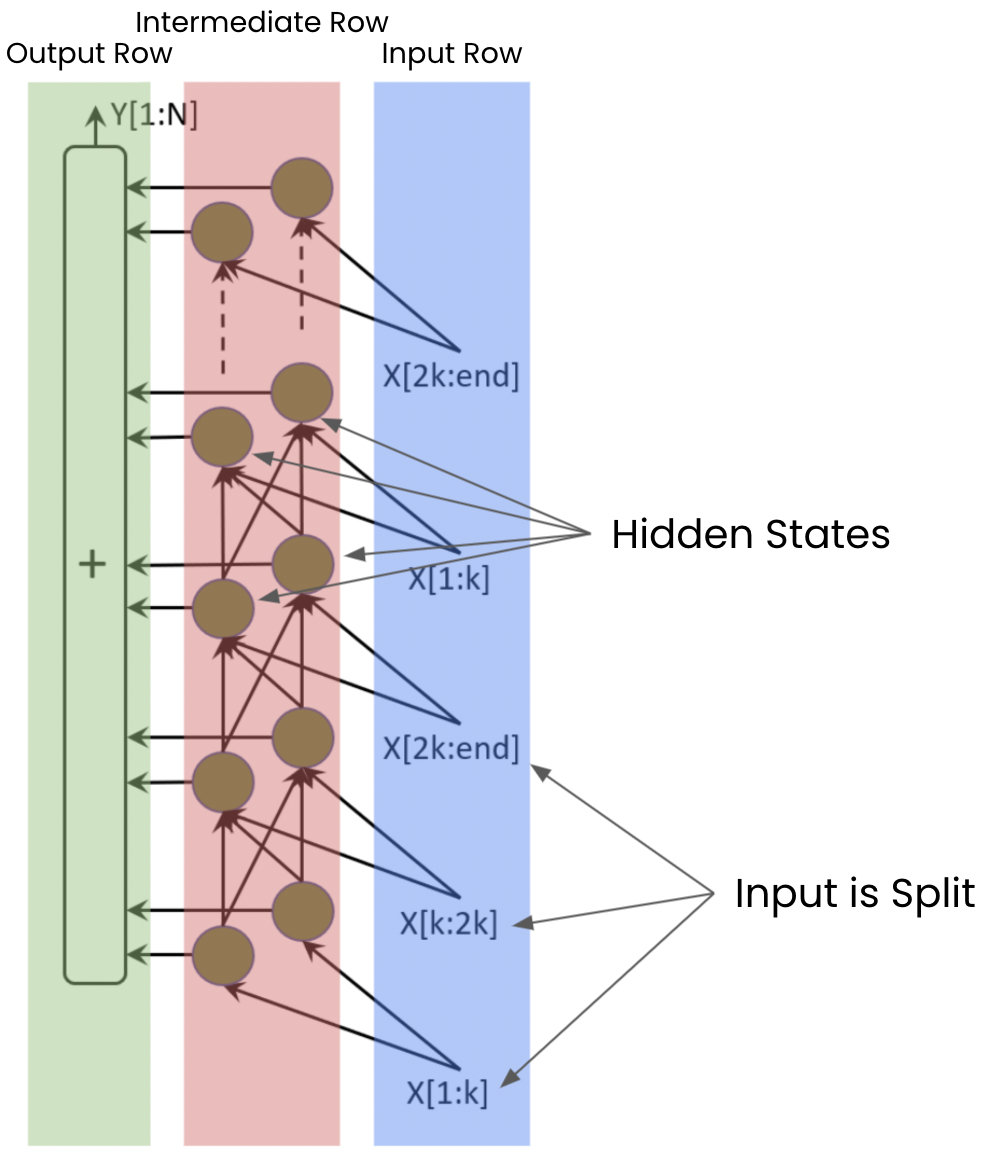
Our input is split up (we can do as many as we want) and passed on repeatedly to the intermediate row. This intermediate row consists of hidden layers (we can specify how many we want). These intermediate layers take in the inputs and spits out the output + pass it on to the next hidden states.
Proving Universal Approximation:
Since it's a new NN type, they're going to prove this. They prove that you could structure the SpinalNet in a which in which it matches perfectly with a regular NN, which has universal approximation, thus SpinalNet = universally approximated.
Transfer learning:
Basically, you take another pre-trained NN and copy-and-paste the weights over to another NN - you fine tune it and it yields awesome performance!
Results:
For plain regression they compared their model with a traditional NN -->
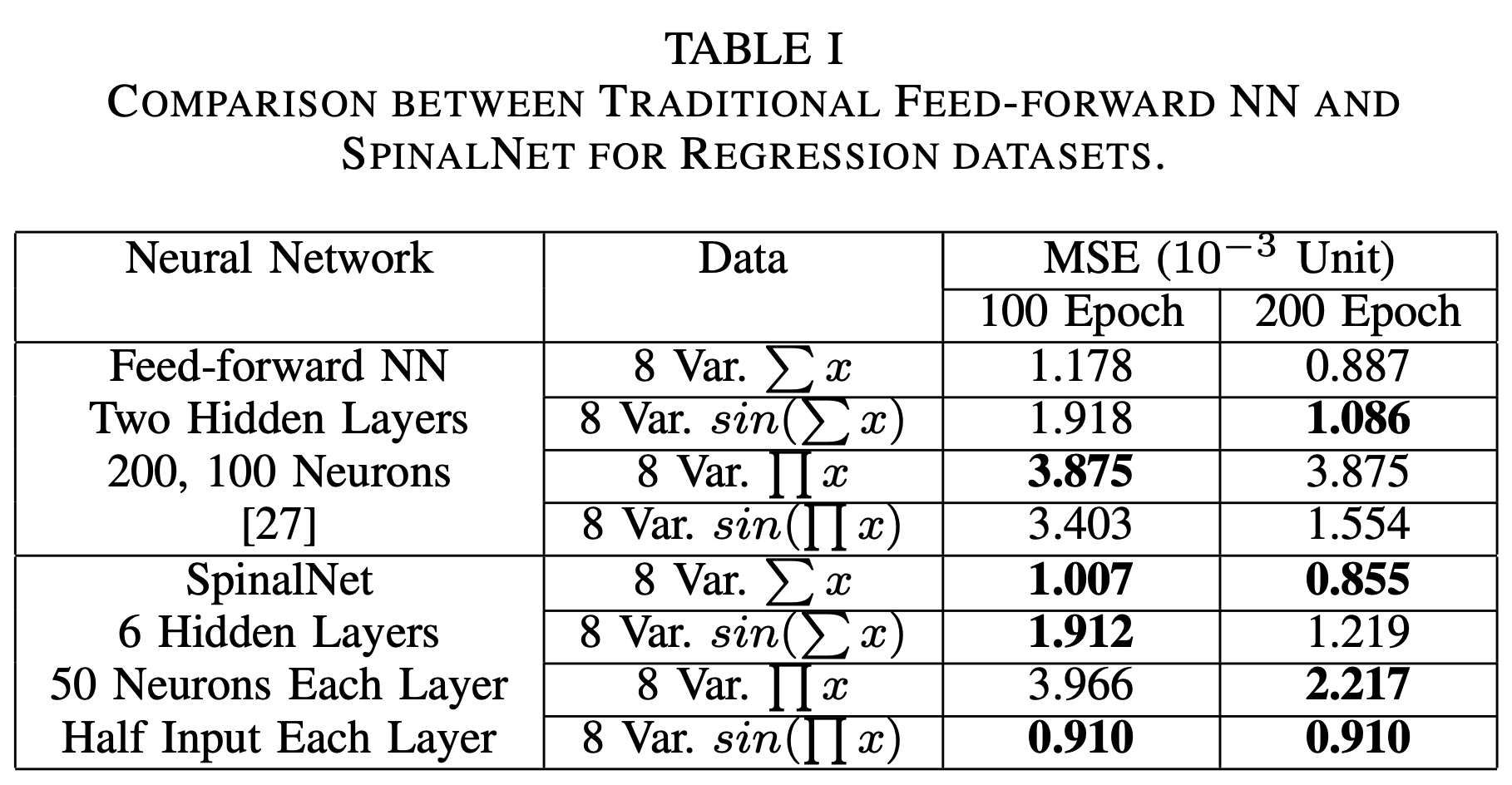
Both NN's have 300 neurons in their hidden state: But SpinalNet has 35.5% less multiplications & parameters, and performs better in 6/8 of the combinations.
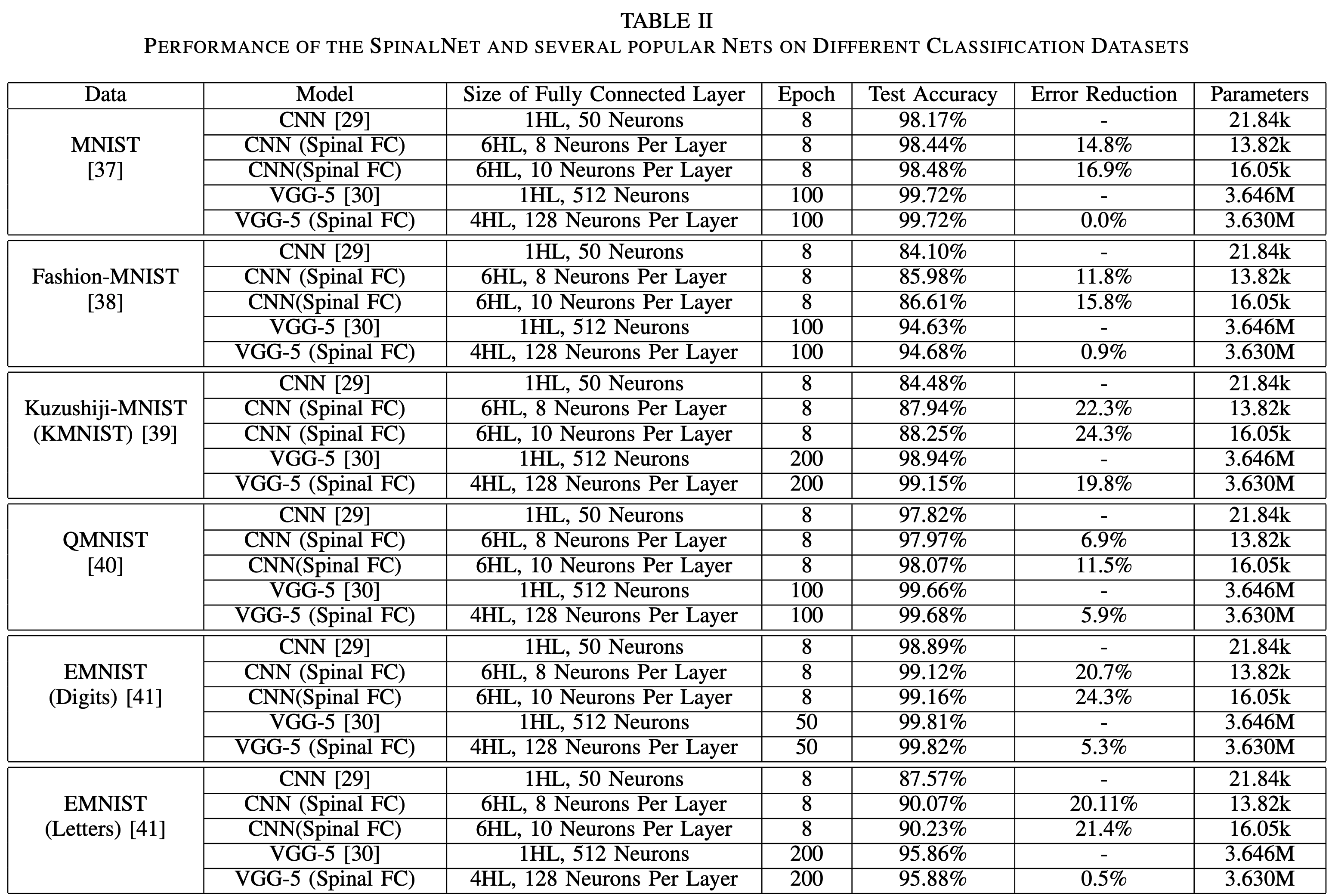
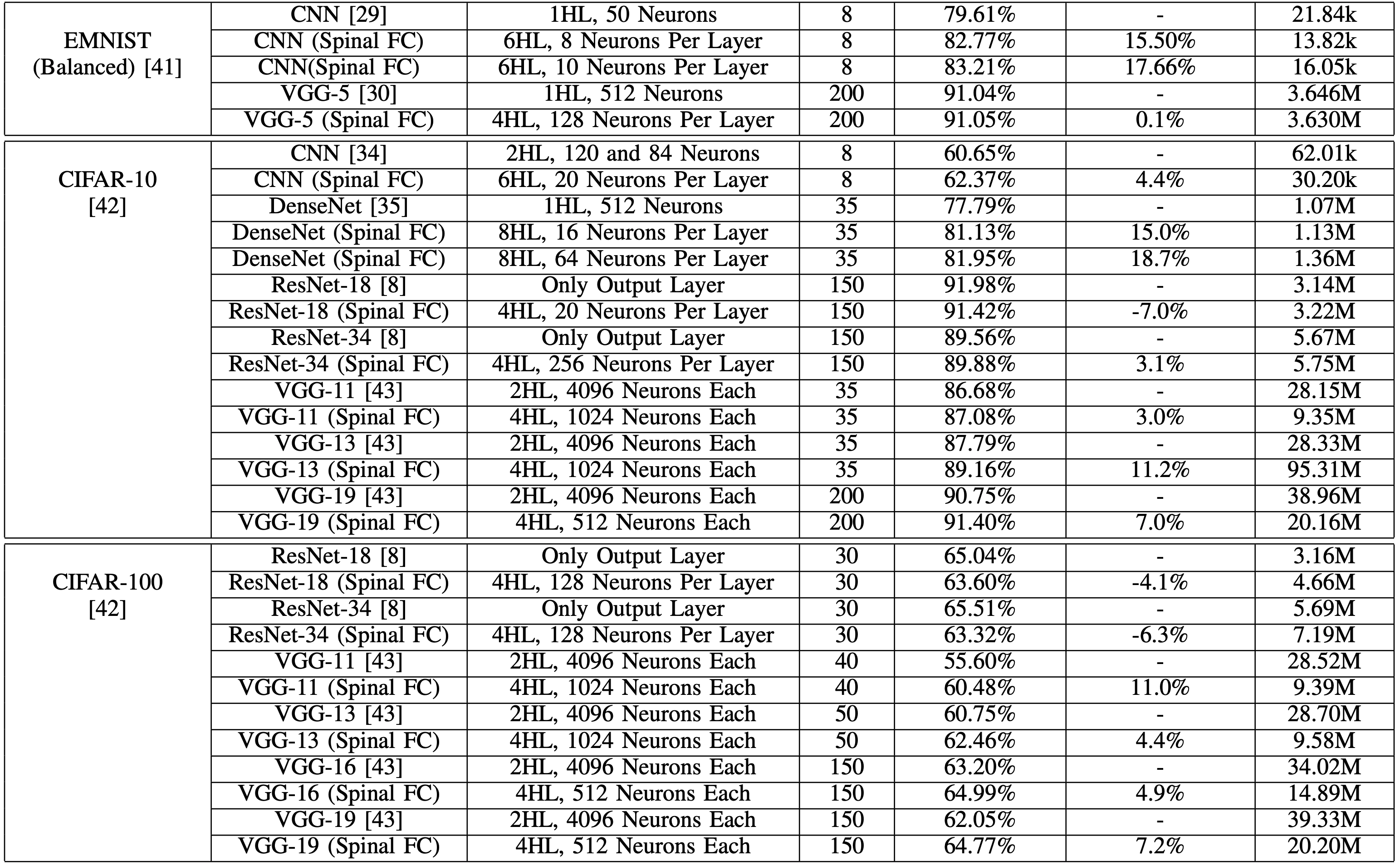
For MNIST they replaced the Fully connected (FC) NN of CNN's (default CNN + VGG-5) and they obtained much better results! 98.17% --> 98.44%, + 48.5% reduction in multiplication + 4% reduction in activation functions. VGG-5 + MNIST + a little data augmentation = 99.72% (top 20 accuracies of MNIST)
[the same is true for the other datasets: Fashion-MNIST (top 5), Kuzushiji-MNIST (SOTA), QMNIST (SOTA), EMNIST (SOTA), CIFAR-10 (good for CNN, DenseNet, VGG, but degrades ResNet), CIFAR-100 (same as CIFAR-10)]
ResNet's FC doesn't have an activation layer, thus we're not helping it. Plus we're adding more hidden layers (although the total amount of hidden neurons remains the same) that screws with the gradients in ResNet.
Alright so let's transfer learn now!
CIFAR-10 - significant improvements in VGG, but when applied to wideResnet, we have slightly worse performance.
CIFAR-100 - VGG = better, wideResNet is better and is top 10
Stanford Cars = VGG = better, wideResNet = Same, not top 20 becuase higher resolution images
SVHN - both = better, but not top 20 becuase pre-training had data that was too off
CLINIC-10 - both = better, top 5
Oxford 102 Flowers - VGG = better, WideResNet = worse but stil top 5 accuracies
Fruits-360 - one of the easist problems. Both = better and they achieved 100%, just like another paper.
Caltech-101 + Bird255 + STL-10 - Both better, SOTA
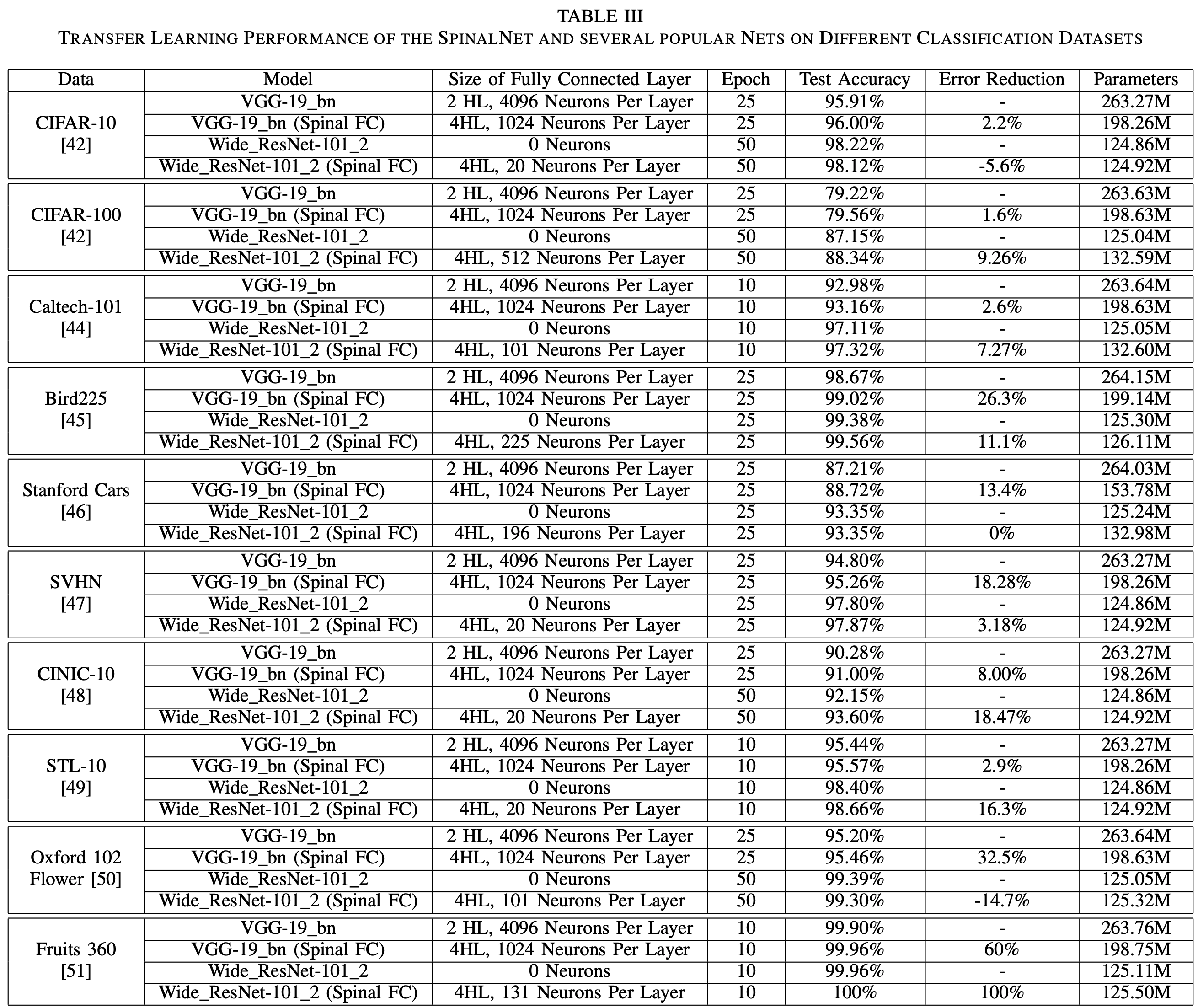
And here are the final results:
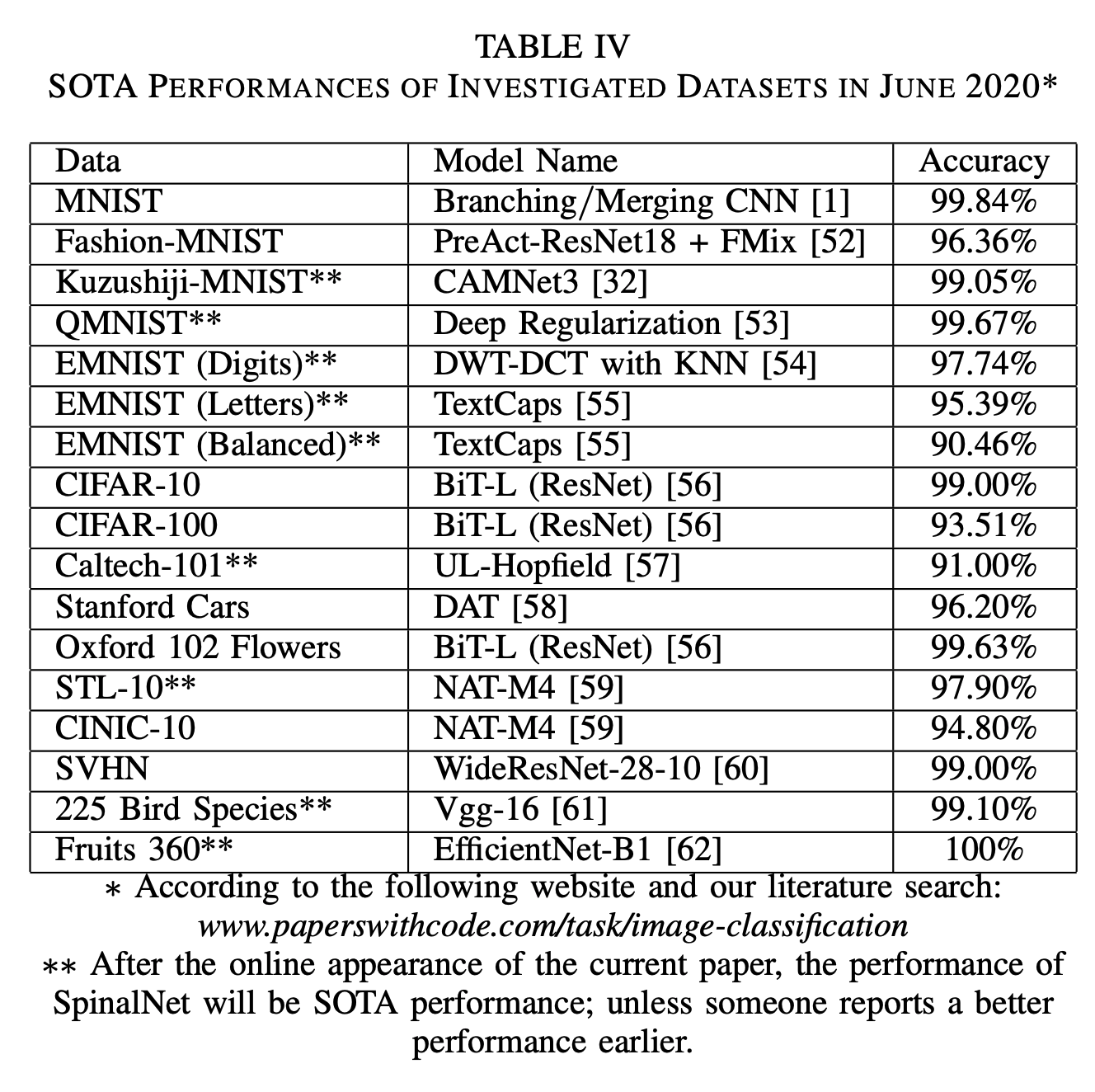
Propsects of SpinalNet:
SpinalNet can be used for Auto-dimension Reduction. SpinalNet does this kind of naturally already, so as long as we condense it within a smaller amount of hidden layers as there are inputs we can do it!.
We could also try and get SpinalNet to increase it's depth. It's linear growth, plus we could slap in gradular training.
SpinalNet in this paper = Independent network or as the FC of a CNN - but we could also use it like a hidden layers within NN's
We can also apply different varaints of SpinalNet to different networks and to different datasets.
Conclusion:
SpinalNet replicates the spinal nervous system of humans in order to increase performance and decrease the computation cost of FC NNs. We can use it as a standalone, or to replace the FC NNs in other networks. By combining SpinalNet with other networks, they obtain SOTA on 4 datasets!
Comments (loading...)
ML Paper Collection
A Collection of Summaries of my favourite ML papers!