
Loading...
Postulate is the best way to take and share notes for classes, research, and other learning.
Tutorial - Building a QGAN to Generate a Two-Qubit State Using Pennylane and Tensorflow
 Laura Gao
Laura GaoA notebook containing the code can be found here.
Generative adversarial networks (GANs) are fundamentally composed of two "characters" - a generator and a discriminator. By putting these two buddies "to war", we will result in an outcome when the data that the generator generates becomes equal to the real data, even though the generator is never told what the real data is. That's essentially the purpose of a GAN - to generate data that mimics some sort of real data, whether it's generating pictures of people that mimics real pictures or generating counterfeit bills that mimic real bills. This blog post will focus on the technical implementation details of a quantum GAN (QGAN) that can generate a 2-qubit state. If you're looking to build a theoretical understanding, I recommend this video.
In a classical GAN, the generator and discriminator are created as neural networks. In a quantum GAN, the generator and discriminator are created as quantum neural networks (QNNs), or, parametized quantum circuits (PQCs). (These two terms refer to the same thing.)

Image source: @EliesMiquel on Twitter
We start off with our imports:
import pennylane as qml
import tensorflow as tf
from pennylane import numpy as np
from matplotlib import pyplot as pltQuantum Circuit Architecture
I used 5 qubits:
Qubit 0 & 1: the 2 qubit state that we are trying to generate
Qubit 2 & 3: the generator's playground
Qubit 4: the generator's guess
num_wires = 5 dev = qml.device('cirq.simulator', wires=num_wires)
The generator QNN/parametized circuit looks like this:
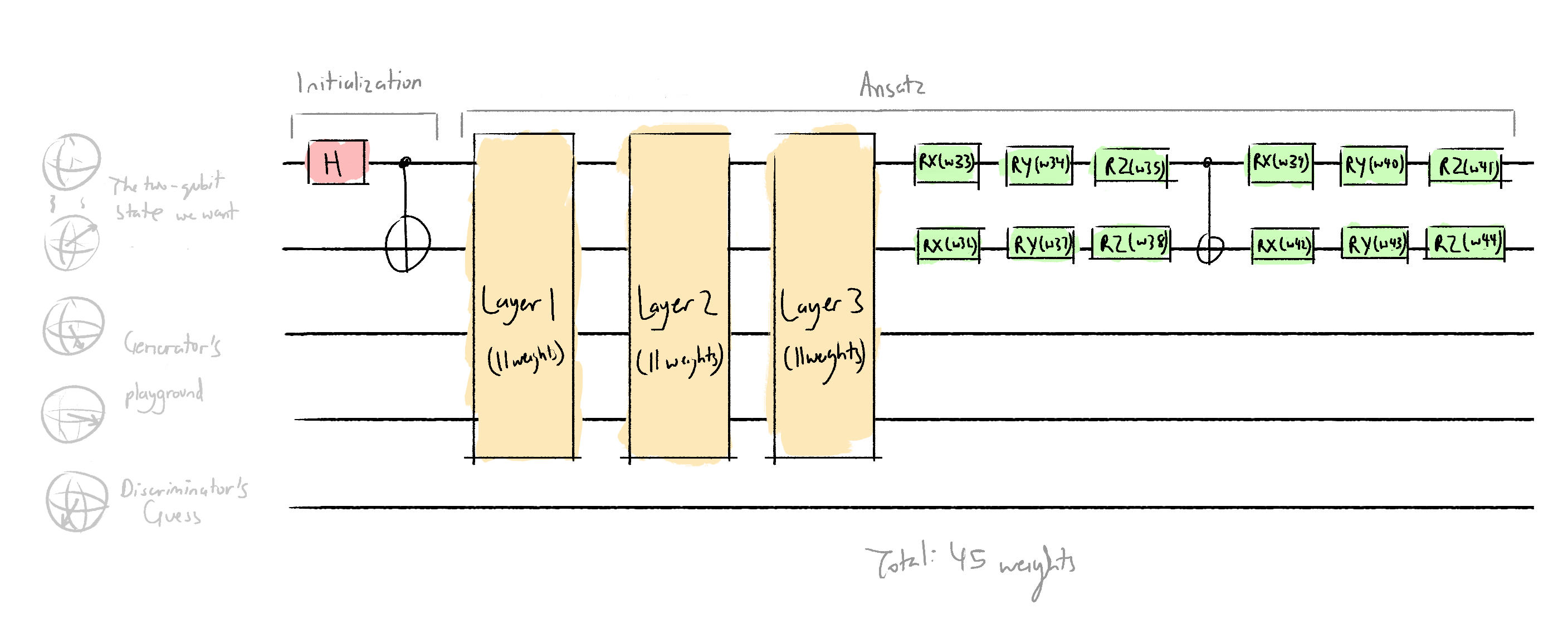
def generator(w, **kwargs):
qml.Hadamard(wires=0)
qml.CNOT(wires=[0,1])
generator_layer(w[:11])
generator_layer(w[11:22])
generator_layer(w[22:33]) # includes w[22], doesnt include w[33]
qml.RX(w[33], wires=0)
qml.RY(w[34], wires=0)
qml.RZ(w[35], wires=0)
qml.RX(w[36], wires=1)
qml.RY(w[37], wires=1)
qml.RZ(w[38], wires=1)
qml.CNOT(wires=[0, 1])
qml.RX(w[39], wires=0)
qml.RY(w[40], wires=0)
qml.RZ(w[41], wires=0)
qml.RX(w[42], wires=1)
qml.RY(w[43], wires=1)
qml.RZ(w[44], wires=1)I chose to use 3 layers, quite arbitrarily, because I don't know how you're meant to choose. In the future, I can experiment with different ansatzes that have more layers. The architecture of each layer is modelled of of the proposed ansatz in Dallaire-Demers and Killoran (2018):
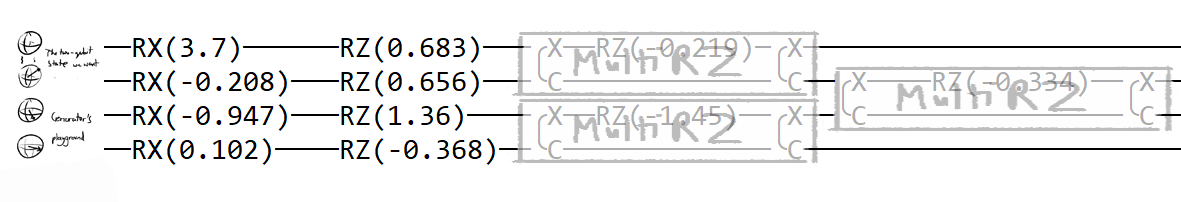
def generator_layer(w):
qml.RX(w[0], wires=0)
qml.RX(w[1], wires=1)
qml.RX(w[2], wires=2)
qml.RX(w[3], wires=3)
qml.RZ(w[4], wires=0)
qml.RZ(w[5], wires=1)
qml.RZ(w[6], wires=2)
qml.RZ(w[7], wires=3)
qml.MultiRZ(w[8], wires=[0, 1])
qml.MultiRZ(w[9], wires=[2, 3])
qml.MultiRZ(w[10], wires=[1, 2])(Using the Pennylane printed circuit because ~~I'm too lazy to draw my own~~ it does the job, hence it meets speck. [^speck])
Here's what the discriminator architecture looks like:
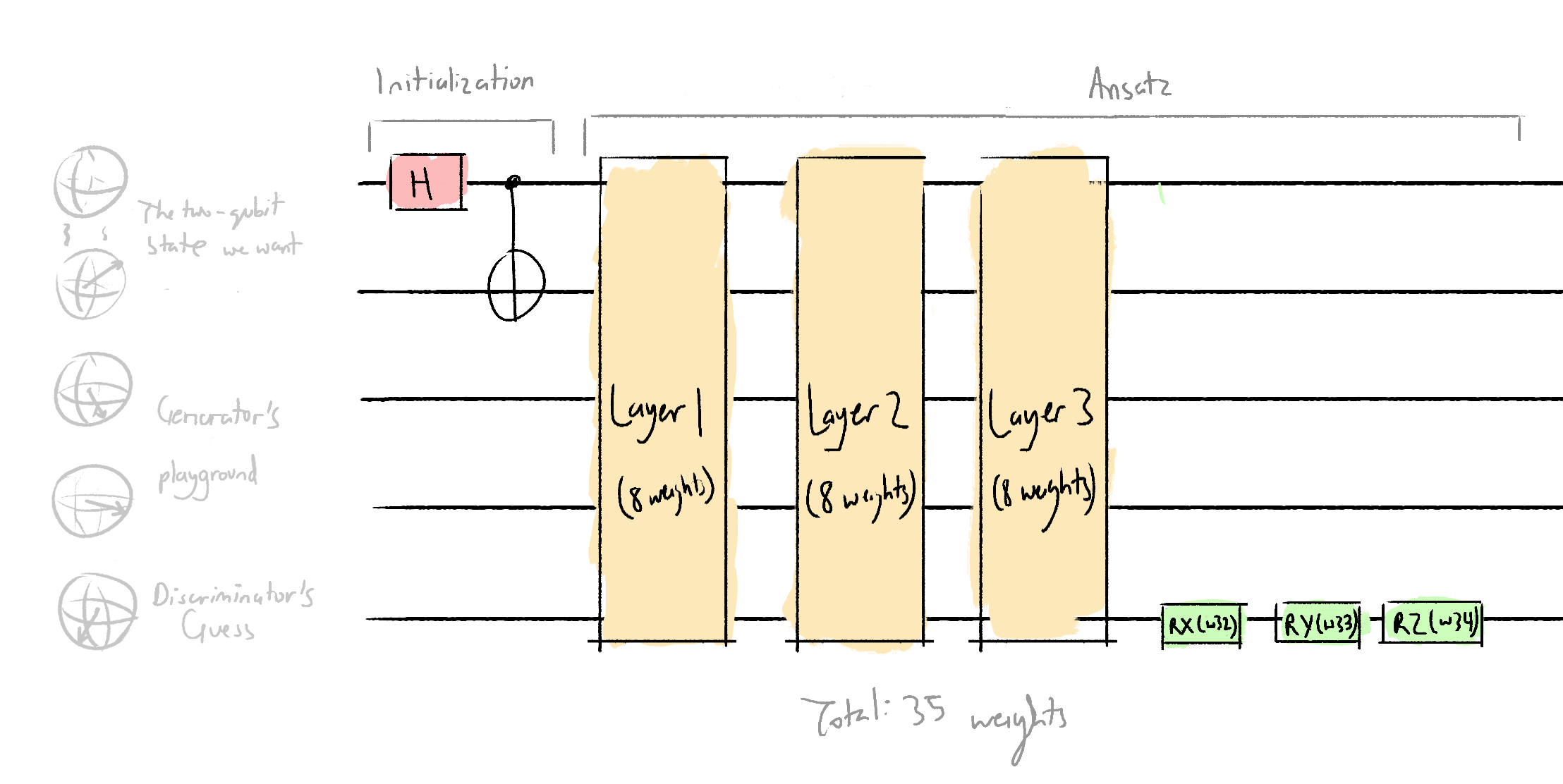
As well as each discriminator layer:

As well as the code to create that:
# the discriminator acts on wires 0, 1, and 4
def discriminator_layer(w, **kwargs):
qml.RX(w[0], wires=0)
qml.RX(w[1], wires=1)
qml.RX(w[2], wires=4)
qml.RZ(w[3], wires=0)
qml.RZ(w[4], wires=1)
qml.RZ(w[5], wires=4)
qml.MultiRZ(w[6], wires=[0, 1])
qml.MultiRZ(w[7], wires=[1, 4])
def discriminator(w, **kwargs):
qml.Hadamard(wires=0)
qml.CNOT(wires=[0,1])
discriminator_layer(w[:8])
discriminator_layer(w[8:16])
discriminator_layer(w[16:32])
qml.RX(w[32], wires=4)
qml.RY(w[33], wires=4)
qml.RZ(w[34], wires=4)The real data circuit architecture:
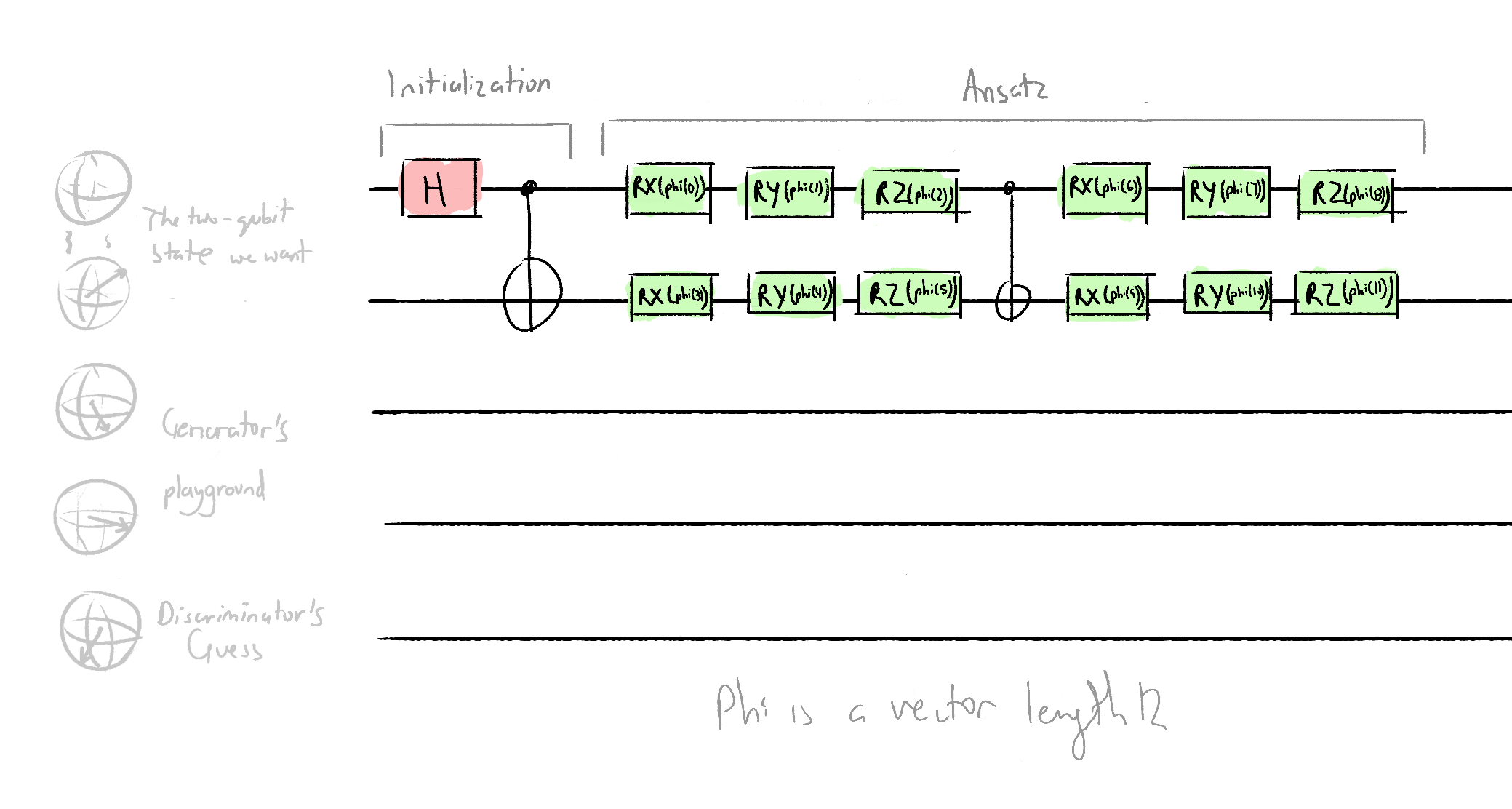
def real_data(phi, **kwargs):
# phi is a list with length 12
qml.Hadamard(wires=0)
qml.CNOT(wires=[0,1])
qml.RX(phi[0], wires=0)
qml.RY(phi[1], wires=0)
qml.RZ(phi[2], wires=0)
qml.RX(phi[3], wires=0)
qml.RY(phi[4], wires=0)
qml.RZ(phi[5], wires=0)
qml.CNOT(wires=[0, 1])
qml.RX(phi[6], wires=1)
qml.RY(phi[7], wires=1)
qml.RZ(phi[8], wires=1)
qml.RX(phi[9], wires=1)
qml.RY(phi[10], wires=1)
qml.RZ(phi[11], wires=1)We will use two quantum nodes, just like what we did in the GAN to generate a single qubit state, and just like what we do in all GANs:
Realdata-discriminator circuit - this circuit will output an expectation value that is proportional to the probability of the discriminator classifying real data as real
Generator-discriminator circuit - this circuit will output an expectation value that is proportional to the probability of the discriminator classifying fake data as real
We return the expectation value of the wire 4 for both QNodes. In the Pennylane tutorial, the expectation value was taken in the PauliZ basis. I don't know why the PauliZ basis was chosen or why it was chosen, but to play it safe, I also used the PauliZ basis in my model.
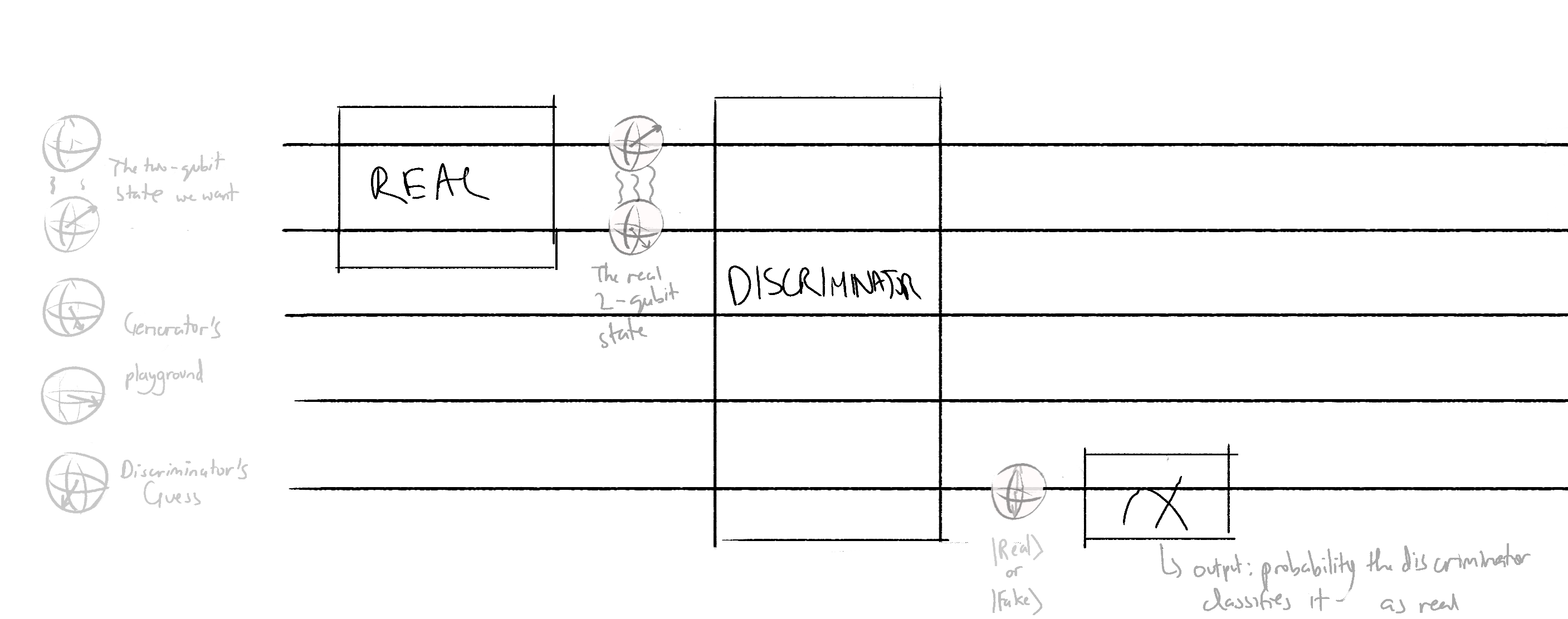
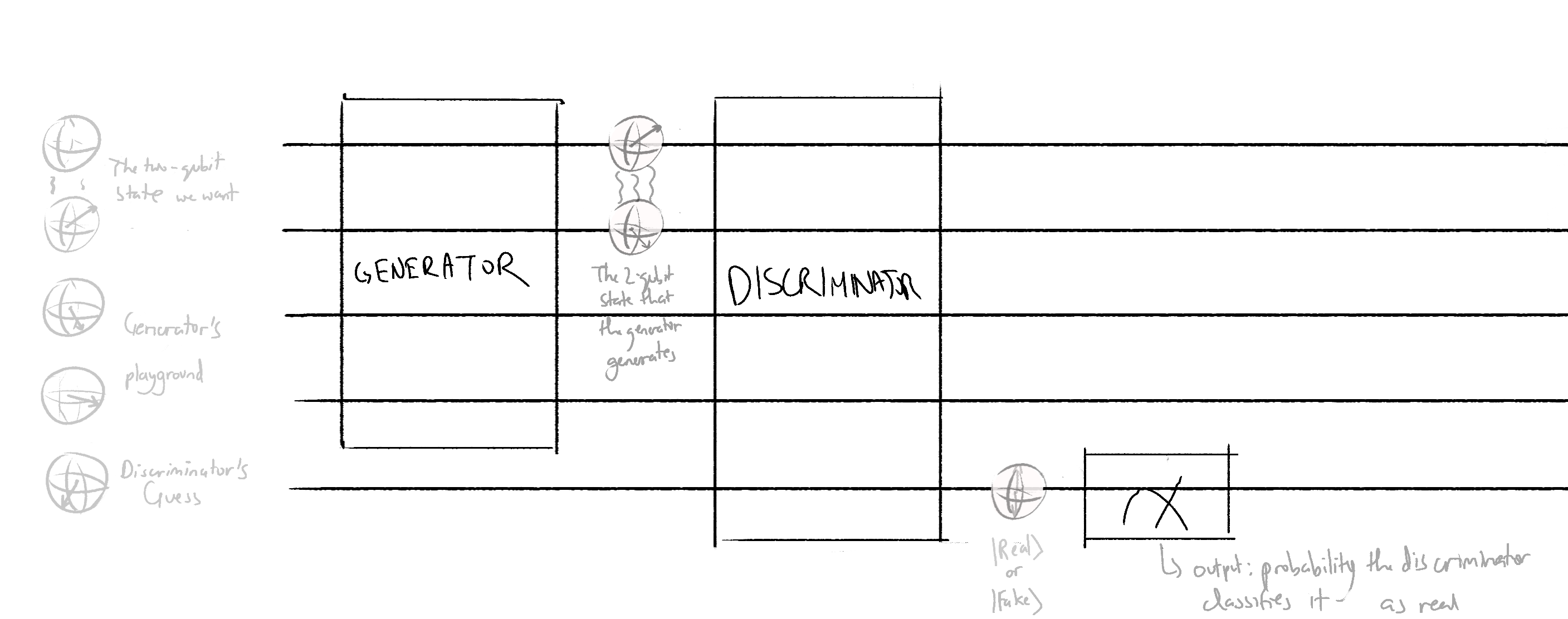
To build these QNodes:
@qml.qnode(dev, interface='tf')
def real_discriminator(phi, discriminator_weights):
real_data(phi)
discriminator(discriminator_weights)
return qml.expval(qml.PauliZ(4))
@qml.qnode(dev, interface='tf')
def generator_discriminator(generator_weights, discriminator_weights):
generator(generator_weights)
discriminator(discriminator_weights)
return qml.expval(qml.PauliZ(4))The circuit architecture is done!
Cost Functions
We will need two cost functions: one for training the generator, and one for training the discriminator. These are defined in the same way as the ones used to generate a single-qubit state:
The discriminator is trying to maximize correct guesses and minimize incorrect ones. The accuracy of the discriminator is given by the probability of the discriminator classifying real data as real - the probability of the discriminator classifying fake data as real, and thus, the cost function will be QNode2 output - QNode1 ouptut.
The generator is trying to maximize how much it can fool the generator, so its accuracy is given by the probability of the discriminator classifying fake data as real, and its cost function would just be the additive inverse of that, aka the QNode2 output.
def probability_real_real(discriminator_weights):
# probability of guessing real data as real
discriminator_output = real_discriminator(phi, discriminator_weights) # the output of the discriminator classifying the data as real
probability_real_real = (discriminator_output + 1) / 2
return probability_real_real
def probability_fake_real(generator_weights, discriminator_weights):
# probability of guessing real fake as real
# incorrect classification
discriminator_output = generator_discriminator(generator_weights, discriminator_weights)
probability_fake_real = (discriminator_output + 1) / 2
return probability_fake_real
def discriminator_cost(discriminator_weights):
accuracy = probability_real_real(discriminator_weights) - probability_fake_real(generator_weights, discriminator_weights)
# accuracy = correct classification - incorrect classification
cost = -accuracy
return cost
def generator_cost(generator_weights):
accuracy = probability_fake_real(generator_weights, discriminator_weights)
# accuracy = probability that the generator fools the discriminator
cost = -accuracy
return costThe cost functions are done!
Training, aka Optimization
We define the weights and turn them into Tensorflow-objects, because Tensorflow optimizers need their parameters to be Tensorflow-type objects.
# variables
phi = [np.pi] * 12
for i in range(len(phi)):
phi[i] = phi[i] / np.random.randint(2, 11)
num_epochs = 30
eps = 1
initial_generator_weights = np.array([np.pi] + [0] * 44) + \
np.random.normal(scale=eps, size=(45,))
initial_discriminator_weights = np.random.normal(scale=eps, size=(35,))
generator_weights = tf.Variable(initial_generator_weights)
discriminator_weights = tf.Variable(initial_discriminator_weights)Declare our Tensorflow optimizer:
opt = tf.keras.optimizers.SGD(0.4)To make it easy to train the generator and discriminator against each other, we will define functions:
def train_discriminator():
for epoch in range(num_epochs):
cost = lambda: discriminator_cost(discriminator_weights)
# you need lambda because discriminator weights is a tensorflow object
opt.minimize(cost, discriminator_weights)
if epoch % 5 == 0:
cost_val = discriminator_cost(discriminator_weights).numpy()
print('Epoch {}/{}, Cost: {}, Probability class real as real: {}'.format(epoch, num_epochs, cost_val, probability_real_real(discriminator_weights).numpy()))
if epoch == num_epochs - 1:
print('\n')
def train_generator():
for epoch in range(num_epochs):
cost = lambda: generator_cost(generator_weights)
opt.minimize(cost, generator_weights)
if epoch % 5 == 0:
cost_val = generator_cost(generator_weights).numpy()
print('Epoch {}/{}, Cost: {}, Probability class fake as real: {}'.format(epoch, num_epochs, cost_val, probability_fake_real(generator_weights, discriminator_weights).numpy()))
if epoch == num_epochs - 1:
print('\n')
Now it's time for the fun part, what all this work was for! Start putting the discriminator and generator to war by training them against each other:
train_discriminator()
train_generator()Out:
Epoch 0/30, Cost: -0.14299175143241882, Probability class real as real: 0.7159662395715714
Epoch 5/30, Cost: -0.16198615729808807, Probability class real as real: 0.6768261790275574
Epoch 10/30, Cost: -0.1782488077878952, Probability class real as real: 0.6543751358985901
Epoch 15/30, Cost: -0.1930706650018692, Probability class real as real: 0.6391105055809021
Epoch 20/30, Cost: -0.20613813400268555, Probability class real as real: 0.6282232850790024
Epoch 25/30, Cost: -0.2171032577753067, Probability class real as real: 0.6213741898536682
Epoch 0/30, Cost: -0.8329757153987885, Probability class fake as real: 0.8329757153987885
Epoch 5/30, Cost: -0.9646678753197193, Probability class fake as real: 0.9646678753197193
Epoch 10/30, Cost: -0.9865575945004821, Probability class fake as real: 0.9865575945004821
Epoch 15/30, Cost: -0.9927986208349466, Probability class fake as real: 0.9927986208349466
Epoch 20/30, Cost: -0.994613244663924, Probability class fake as real: 0.994613244663924
Epoch 25/30, Cost: -0.9951627007685602, Probability class fake as real: 0.9951627007685602And again:
train_discriminator()
train_generator()Out:
Epoch 0/30, Cost: 0.17858757823705673, Probability class real as real: 0.7850917801260948
Epoch 5/30, Cost: -0.5038639940321445, Probability class real as real: 0.9411767162382603
Epoch 10/30, Cost: -0.6774246245622635, Probability class real as real: 0.8727522641420364
Epoch 15/30, Cost: -0.6971746385097504, Probability class real as real: 0.8618842959403992
Epoch 20/30, Cost: -0.7033393457531929, Probability class real as real: 0.8595472723245621
Epoch 25/30, Cost: -0.7069503888487816, Probability class real as real: 0.859374426305294
Epoch 0/30, Cost: -0.4890183061361313, Probability class fake as real: 0.4890183061361313
Epoch 5/30, Cost: -0.9917170405387878, Probability class fake as real: 0.9917170405387878
Epoch 10/30, Cost: -0.997629354824312, Probability class fake as real: 0.997629354824312
Epoch 15/30, Cost: -0.9991561353090219, Probability class fake as real: 0.9991561353090219
Epoch 20/30, Cost: -0.9995477425254649, Probability class fake as real: 0.9995477425254649
Epoch 25/30, Cost: -0.9996513455698732, Probability class fake as real: 0.9996513455698732You can keep pitting these circuits against each other for as many times as you want! As for us, we'll be satisfied with a 70% discriminator accuracy and 99% generator accuracy.
Validation
obs = [qml.PauliX(0), qml.PauliY(0), qml.PauliZ(0), qml.PauliX(1), qml.PauliY(1), qml.PauliZ(1)] # oh this is the observation matrix
bloch_vector_real = qml.map(real_data, obs, dev, interface="tf") # These qml.mapped objects are essentially mini-circuits / mini-qnodes. they functionally act this wayl.
bloch_vector_generator = qml.map(generator, obs, dev, interface="tf")
bloch_vector_realz = bloch_vector_real(phi) # here: you pass phi through the mini-qnode / mini-circuit.
bloch_vector_generatorz = bloch_vector_generator(generator_weights) # calling it with a z at the end because adding _2 at the end is boring. for a lack of better name.
difference = np.absolute(bloch_vector_generatorz - bloch_vector_realz)
accuracy = difference / (np.pi) # the max rotation is a 2pi rotation
# no but should it be divided by pi and not 2pi because a rotation of pi is maximum far-away-ness.
# Find the mean of the accuracy
average_accuracy = 0
for i in range(len(accuracy)):
average_accuracy += accuracy[i]
average_accuracy = average_accuracy / len(accuracy)
average_accuracy = 1 - average_accuracy
print("Real Bloch vector: {}".format(bloch_vector_realz))
print('')
print("Generator Bloch vector: {}".format(bloch_vector_generatorz))
print('')
print("Difference: {}".format(difference))
print('')
print("Accuracy: {}".format(average_accuracy))Out:
Real Bloch vector: [ 4.49031681e-01 8.68634649e-01 1.49011612e-07 -7.46617287e-01
5.78252882e-01 -2.53656507e-01]
Generator Bloch vector: [ 0.32962847 0.81327445 0.24301034 -0.68318889 0.49043131 -0.35765988]
Difference: [0.11940321 0.0553602 0.24301019 0.0634284 0.08782157 0.10400337]
Accuracy: 0.9642948114019914I wrote a blog post to explain why the above code is successful at retreiving the Bloch vectors.
With that, we have successfully generated the two-qubit state!
Footnote
[^speck]: Speck is an idea that Seth Godin talks about which states that the definition of whether something is high quality is if it meets speck. If your work has met speck, yes, it can be made better, but there's no point of making it any better.
Comments (loading...)
Quantum computing
Working notes from learning QC